Loader Redshift
Redshift is a fully managed, petabyte-scale data warehouse service in the cloud designed to handle large-scale data analytics. It enables organizations to efficiently store and analyze vast amounts of data using a massively parallel processing (MPP) architecture.
Business value in CDP
As a loader to export data from CDP to Redshift, users can leverage Redshift's native capabilities for data ingestion and transformation. CDP data can be seamlessly transferred to Redshift, allowing organizations to benefit from Redshift's high-performance analytics, scalability, and ease of use. This integration facilitates streamlined and efficient data movement, enabling businesses to derive valuable insights from their data housed in CDP within the powerful analytics environment of Amazon Redshift.
Setting up the loader in MI
Redshift loader enables the loading of the data from Meiro Integrations to Redshift. Files from Meiro are loaded to an AWS S3 bucket, and from there to Redshift.
Data In/Data Out
| Data In |
In order to use a loader, files need to be stored in |
| Data Out | N/A |
Learn more: about the folder structure here.
Parameters
AWS S3 Configuration
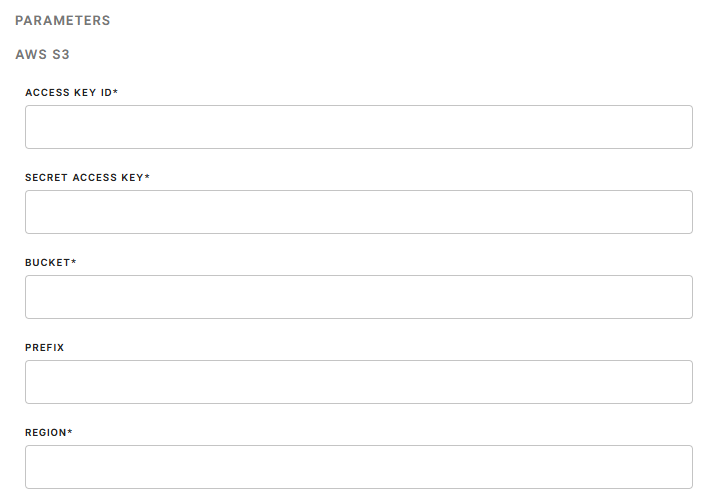
|
ACCESS KEY ID |
|
Your AWS Access Key ID, looks like AKIA**** Create it in the Credential section of your AWS S3 account: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File
Learn more about how to create your Redshift Access Key ID here. |
| SECRET ACCESS KEY |
|
The AWS Secret Access Key is provided by the AWS when you create a new AWS Access Key: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File.
Learn more about how to create your Redshift Secret Access Key here. |
| BUCKET |
(required) |
Provide a Redshift bucket name, which is a globally unique identifier. |
|
PREFIX |
|
Provide a prefix to key names of the files prefix. If not indicated, the files will be uploaded without any prefix in the Redshift bucket.
For example, if you wish to upload data in the directory new_folder in your Redshift bucket, please use new_folder (for longer prefix: |
|
REGION |
(required) |
Leave blank ('') to autodetect the region. For full reliability, set it explicitly. |
Database Configuration
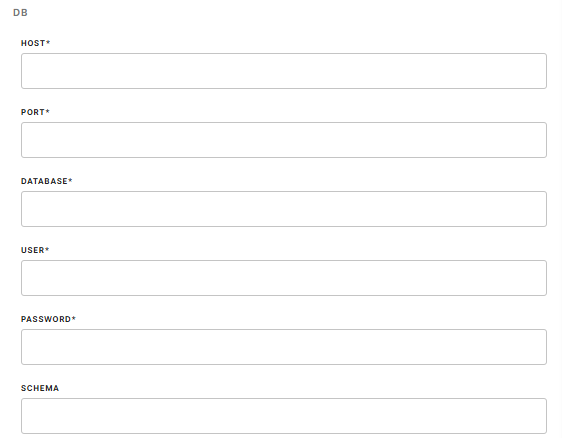
| HOST | host(required) |
Name of the server that hosts the database. Hostname of your Redshift server. |
| PORT | port(required) |
The port number you want to connect to Redshift. |
| DATABASE | database(required) |
Name of the database. |
| USER |
(required) |
Database username. |
| PASSWORD | #password (required) |
Database password. |
| SCHEMA | schema(required) |
Default: publicName of the schema. Defines the namespace within the database. |
SSH Configuration (if enabled)

| ENABLED | enabled |
Check if SSH tunneling is required. |
|
PRIVATE KEY |
private_key |
SSH private key in the following format: -----BEGIN RSA PRIVATE KEY----- MIIEpAIBAAKCAQEA... ...fdsafd== -----END RSA PRIVATE KEY----- |
| SSH USER | username |
SSH username. |
|
SSH HOST |
ssh_host |
Hostname of the SSH server. |
Table Configuration
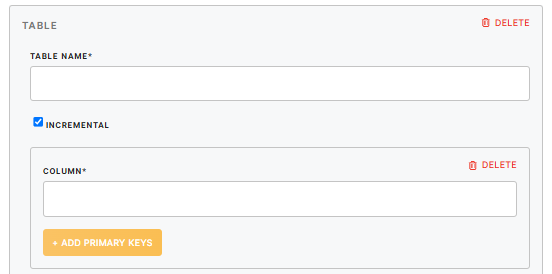
| TABLE NAME | table_id (required) |
Unique identifier for the table, used as both the CSV file name and the Redshift table name. |
| INCREMENTAL | incremental |
Enables incremental load. If true, only new or updated rows are inserted; if false, the table is fully replaced. |
| COLUMN | primary_keys |
One or more columns that define the primary key. Cannot be nullable. Used to identify changes in incremental mode. |
Column Configuration
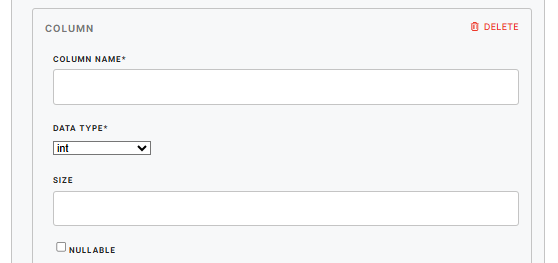
|
COLUMN NAME
|
|
Column identifier, used as both the CSV column name and the destination column name in Redshift. |
| DATA TYPE | data_type (required) |
The data type for the column. Supported data types:
|
| SIZE | size(optional) |
The maximum length of the column value. Data types that require it:
|
| NULLABLE | nullable |
If checked, then the data with empty strings is loaded as NULL values in the destination database (in this case
If unchecked and data contains empty strings, then the loader returns an error message. For example: “Cannot insert the value NULL into column XY, the column does not allow nulls. INSERT fails.”
Warning: Primary key columns must not be nullable. Otherwise, the loader will throw: |
No Comments