Loader Pipedrive
Pipedrive is a customer relationship management (CRM) platform designed to streamline sales processes and enhance team collaboration. It provides a user-friendly interface for managing leads, deals, and contacts, enabling businesses to track and optimize their sales pipelines effectively.
Business value in CDP
By leveraging Pipedrive as a loader, businesses can effortlessly migrate customer and sales-related data from their CDP, such as valuable customer insights and interactions, into Pipedrive's organized structure. This integration facilitates a more holistic view of customer relationships, empowering sales teams with enriched data to make informed decisions and improve overall efficiency in their sales processes within the Pipedrive CRM ecosystem.
Setting up the loader in MI
This component allows you to load data into Pipedrive.
Data In/ Data Out
| Data In | Upload all files in /data/in/files |
| Data Out | N/A |
Learn more: about the folder structure here.
Prerequisite
On Pipedrive, you must ensure the callback URL is linked to Meiro integrations. This can be found on the Marketplace manager tab under OAuth & Access scopes.
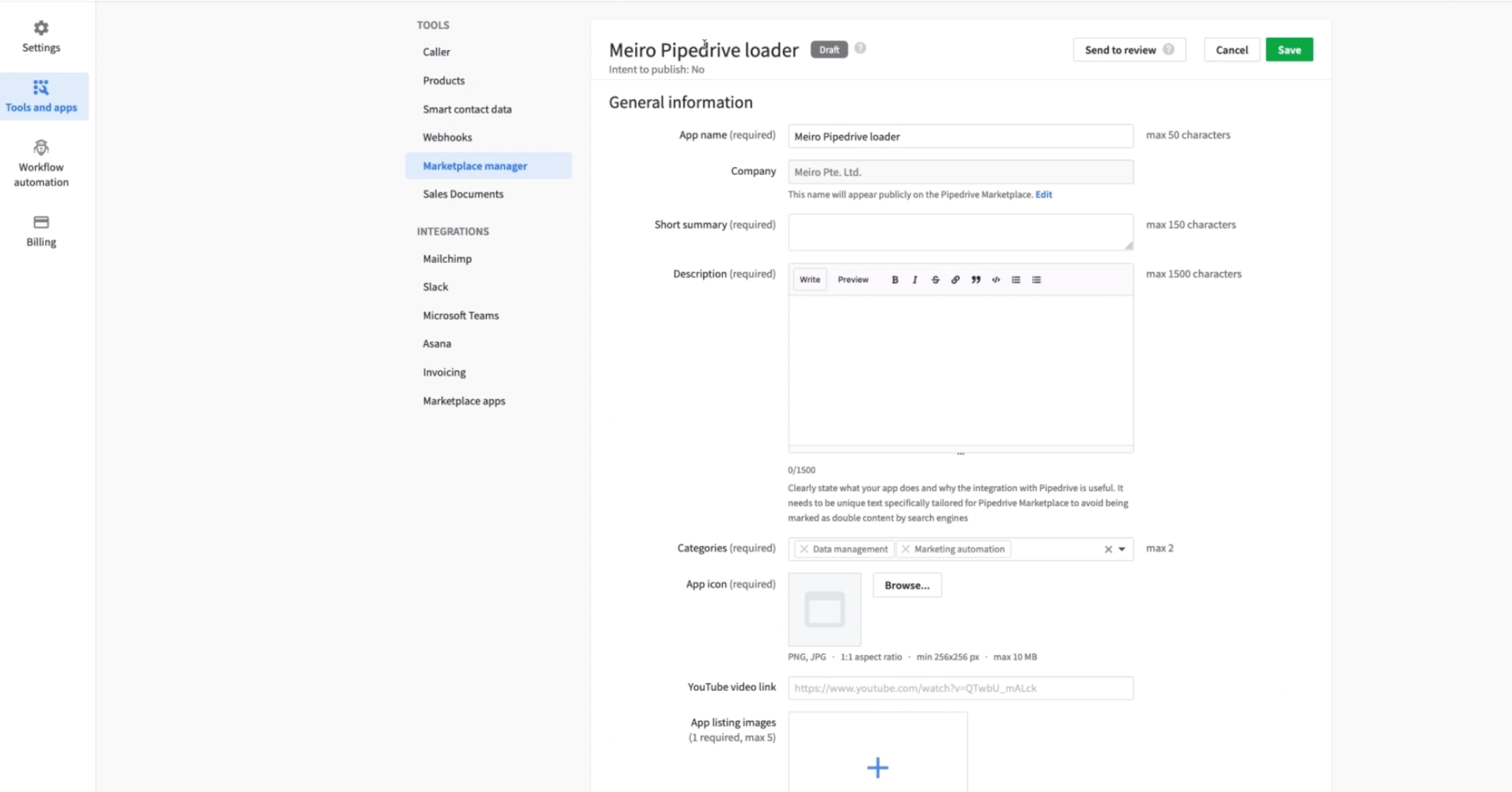
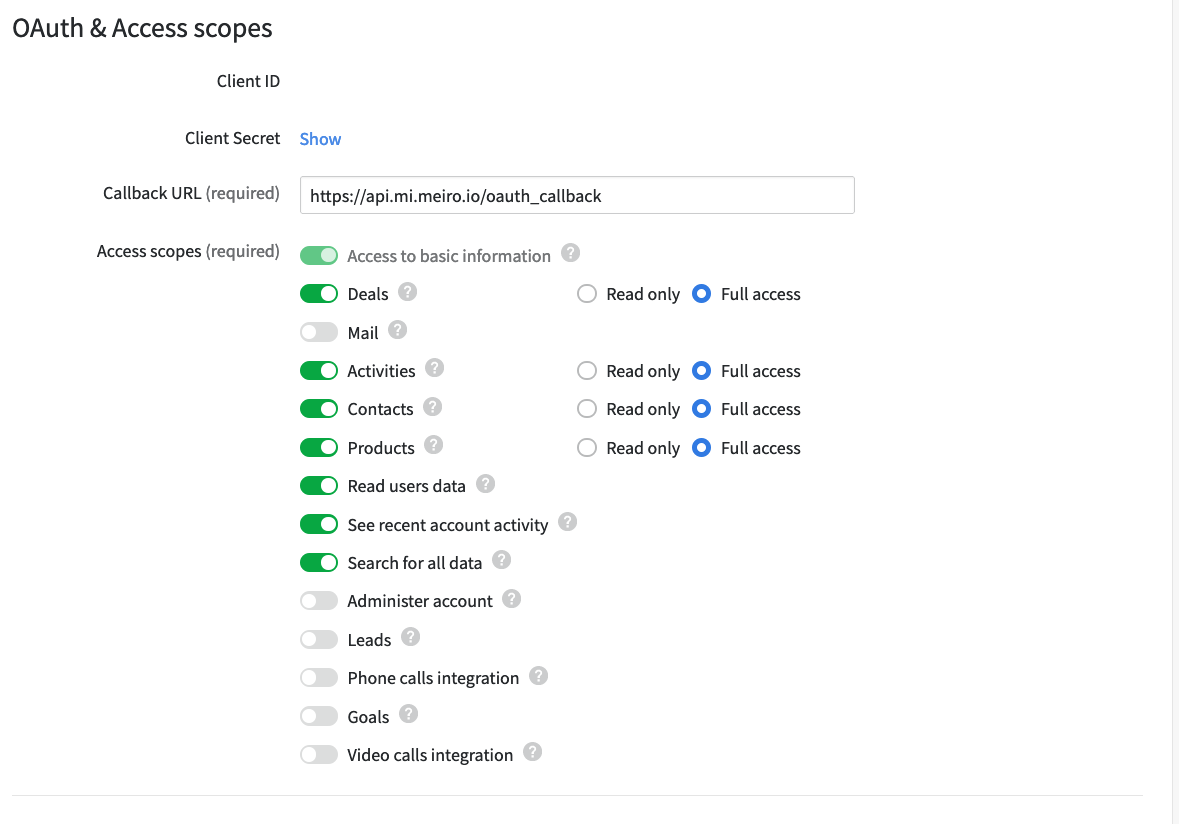
Ensure that you have set up the Pipedrive OAuth repository. You will need the client ID and client secret for it.

Upon creating your loader Pipedrive configuration, authorize Pipedrive by clicking on the green "Authorize" button and give it an account name (optional).
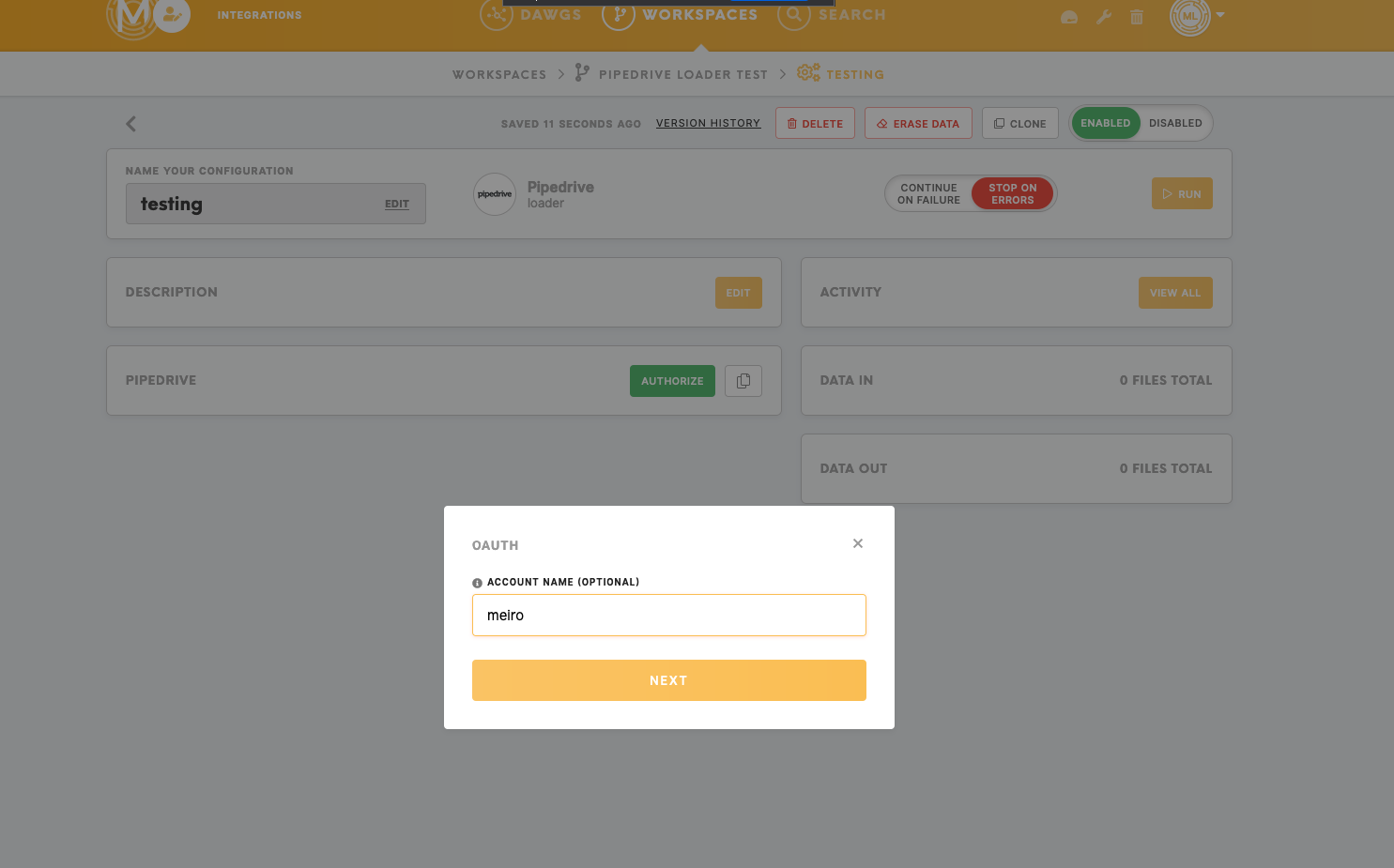
It will lead you to the Pipedrive website to confirm authorisation.
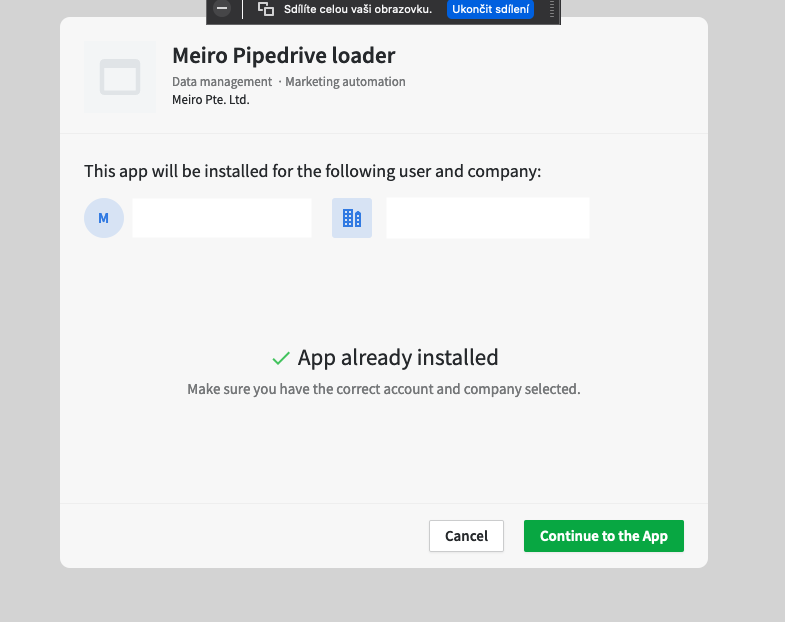
Pipedrive will be authorized and ready to use.

Parameters
No parameters need to be filled. Components work automatically upon authorization.
| How does Pipedrive work upon loading data? |
|
| Where does the data end up after I load them? |
Activities are assigned to specific persons, deals, or organisations depending on the IDs known in the activities.csv file. For persons: New person card is created or overwritten (updated) by new information given in persons.csv When updating ID of person needs to be known as a required parameter.
|
| Does it overwrite data with the same name? |
This will depend on the input file specified in Data In. Example:
|
| Is there an option of incremental load? | The current version of the Pipedrive loader does not support an incremental load. |


No Comments