Loader Google BigQuery
Google BigQuery is a prominent platform in the data analytics and storage domain, offering businesses a robust solution for managing and analyzing large datasets. With an emphasis on practical data processing, Google BigQuery enables businesses to efficiently handle vast amounts of data, supporting informed decision-making and analysis.
Business Value in CFP
Integrating CDP and BigQuery allows businesses to leverage their customer data effectively, facilitating seamless data transfer and analysis. By utilizing Google BigQuery within a CDP ecosystem, businesses can optimize their data management processes and gain valuable insights without relying on complex marketing language.
Setting up the loader in MI
For setting BigQuery as a destination within Meiro Integration, use the Google BigQuery loader component.
Data In/Data Out
| Data In | Upload all files into /data/in/files |
| Data Out | N/A |
Learn more: about the folder structure here.
Parameters

All parameters are set on Google:
| Project (required) | Google project name. |
| Dataset (required) | Google dataset. |
Learn more: Datasets are top-level containers that are used to organize and control access to your tables and views. Learn more about datasets here.
Table
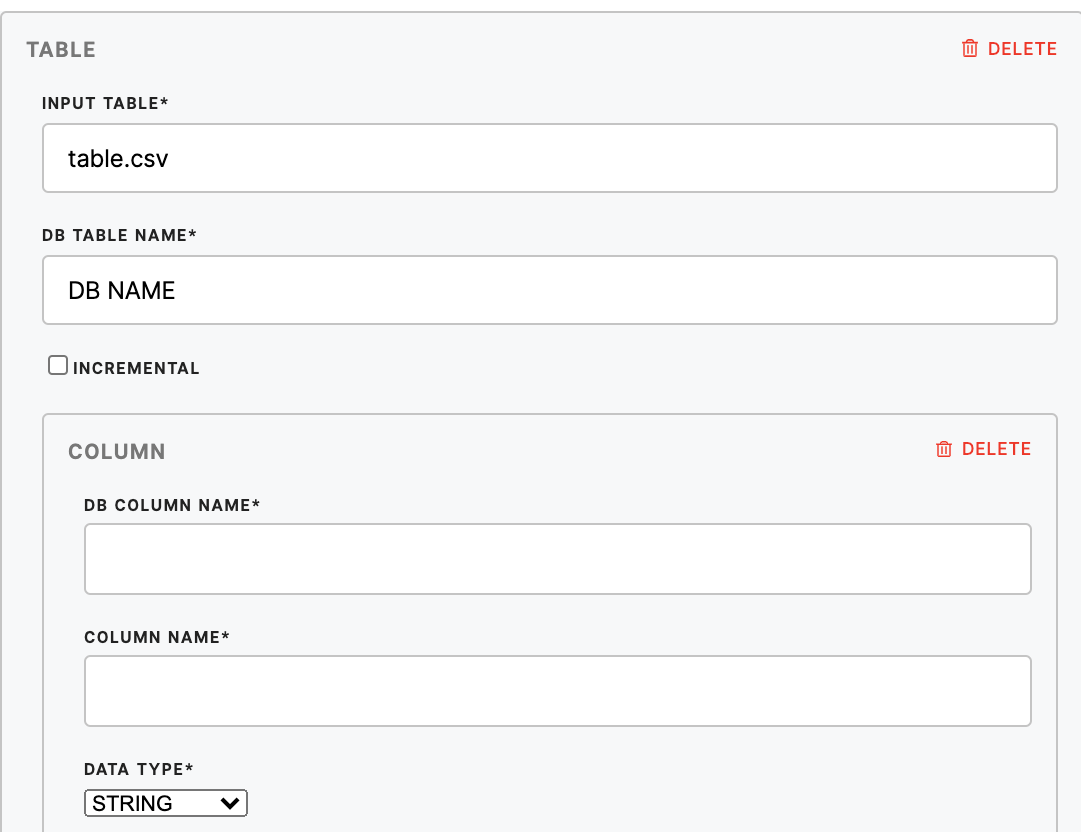
| Input Table (required) | Name of the table you want to load to the database. |
| DB Table Name (required) | Database table name. |
| Incremental | Signifies if you want to load the data by overwriting whatever is in the database or incrementally. |
| DB Column Name (required) | Database column name. |
| Column Name (required) | The name of the column in the input table you want to load to the database. |
| Data Type (required) | The data type can be string, int64, float64, boolean or timestamp. |
Google BigQuery Loader Permissions
If a client is hesitant about granting roles to the service account for the BigQuery Loader, here's an explanation of each role:
-
BigQuery Data Owner (
roles/bigquery.dataOwner) -
Grants full control over datasets, including managing access policies and sharing tables.
-
Not needed in production for loaders, unless full dataset-level management is required.
-
May be useful in testing environments.
-
BigQuery Job User (
roles/bigquery.jobUser) -
Allows dataset creation but does not allow writing to or reading from tables.
-
Generally not needed for loaders.
-
BigQuery Data Editor / BigQuery Writer User (
roles/bigquery.dataEditor) -
Grants permissions to insert, update, and delete table data.
-
Also includes permission to create datasets (bigquery.datasets.create).
-
Covers all writing needs for loaders, including dataset creation in production.
-
BigQuery User (
roles/bigquery.user) -
Allows submitting query, load, and extract jobs.
-
Required to initiate load operations.
Minimum Roles Required for Running the Loader in Production
To run the BigQuery Loader in production, the following roles are required:
✅ BigQuery Job User
✅ BigQuery Data Editor
These two roles are sufficient for submitting load jobs, writing data, and creating datasets..
🔹 BigQuery Data Owner
Optional – only needed in testing or if your loader manages dataset-level access or deletion.
Using a Custom Role
Instead of the built-in permission roles, you can use a custom role. If preferred, you can define a custom IAM role with just the required permissions:
-
bigquery.datasets.create -
bigquery.datasets.get -
bigquery.datasets.list -
bigquery.tables.create -
bigquery.tables.get -
bigquery.tables.delete -
bigquery.jobs.create -
resourcemanager.projects.list
FAQ
|
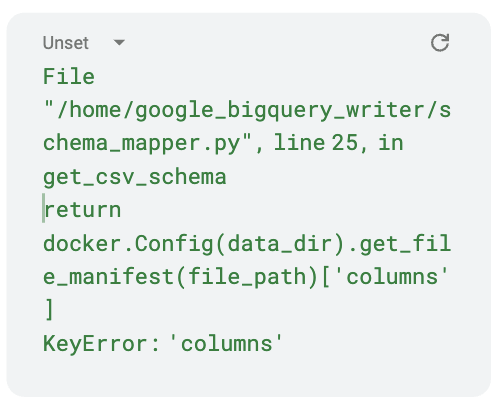
My loading did not complete, with the following error message. How do I fix it?
|
The loader requires a manifest file with the Create a manifest file based on the code template below. Remember to change the file names, destination names, and fields accordingly based on the CSV that you are trying to load: |
No Comments