Loader Cockroach
Cockroach is an object-relational database management system.
Cockroach uses and extends the SQL language combined with many other features that safely store and scales the most complicated data workloads.
The native data types that are supported include:
- Primitives: Integer, Numeric, String, Boolean
- Structured: Date/Time, Array, Range, UUID
- Document: JSON/JSONB, XML, Key-value (Hstore)
- Geometry: Point, Line, Circle, Polygon
- Customizations: Composite, Custom Types
Learn more: about Cockroach from Cockroach documentation.
The Cockroach loader is used to load data into a table in the Cockroach database.
Requirements
Credentials of the database you would like to connect to:
- Host
- Port
- Name of the database, schema
- User
- Password
However, the exact credentials required may depend on your specific setup, as CockroachDB supports a variety of authentication methods.
If you wish to connect to a database outside of the Meiro Integrations environment, you may need a front-end tool like DBeaver, IntelliJ IDEA, or any other front-end (GUI) tool available online. To learn more about these tools, please refer to their respective documentation online. Connecting via a GUI tool is not mandatory, but it may be useful to access the database outside the Meiro Integrations environment.
Cockroach components work only with CSV tables. Other data formats need to be converted to CSV format by processors.
Features
- One file and multi-file tables,
- Header and no header,
- Custom delimiter,
- Automatic creation of the destination table (all data types as a text for columns) and manual override if the user wants to specify the data type for a column.
Data In/Data Out
| Data In |
The table from the previous component should be saved in a CSV table, and you can specify the table path using various formats. These formats include:
File structure:
ID,CAR,COST,DATE_OF_SALE 1,BWM,400000,2019-09-10 2,Volvo,3000,2019-01-10
Or without header 1,BWM,400000,2019-09-10 2,Volvo,3000,2019-01-10
Warning: |
| Data Out | N/A |
Learn more: about the folder structure here.
Parameters
Table
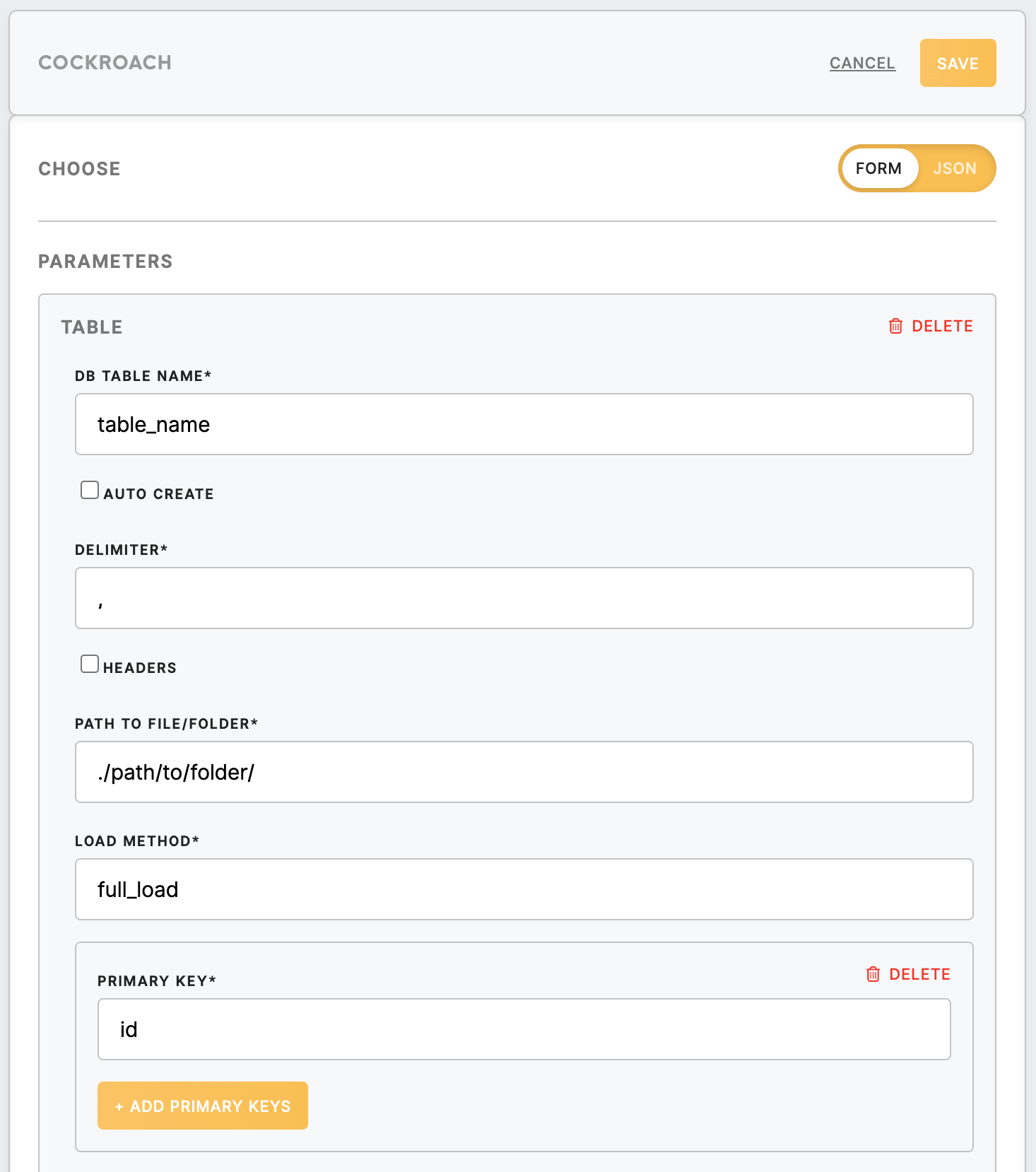
| DB Table Name (required) | Table’s name in the database. |
| Auto Create (true/ false) (optional) | If true, auto-creates columns by headers in CSV files, the type is text, nullable true and default is an empty string. Columns definitions will be ignored. |
| Delimiter (required) | Customer delimiter. |
| Headers (optional) | If true, headers are specified in the CSV files, if false columns will be populated in order in which they are entered. |
| Path to File/ Folder (required) |
Path to the folder with data folders with specifications on the table's name. For example,
For loading all CSV files to the database, folder path |
| Load method (required) | full_load, insert, upsert |
| Full_load method |
Method deletes given tables if they exist. Re-creates them and inserts data from file(s). Note that when using this method, it is important to disable |
| Insert method | The method inserts data into the tables and ignores conflicts. |
| Upsert method | Method upsert data to the tables. In case of conflicts, data will be updated. |
| Primary key (required) | List of primary keys (from columns specified further). |
Column
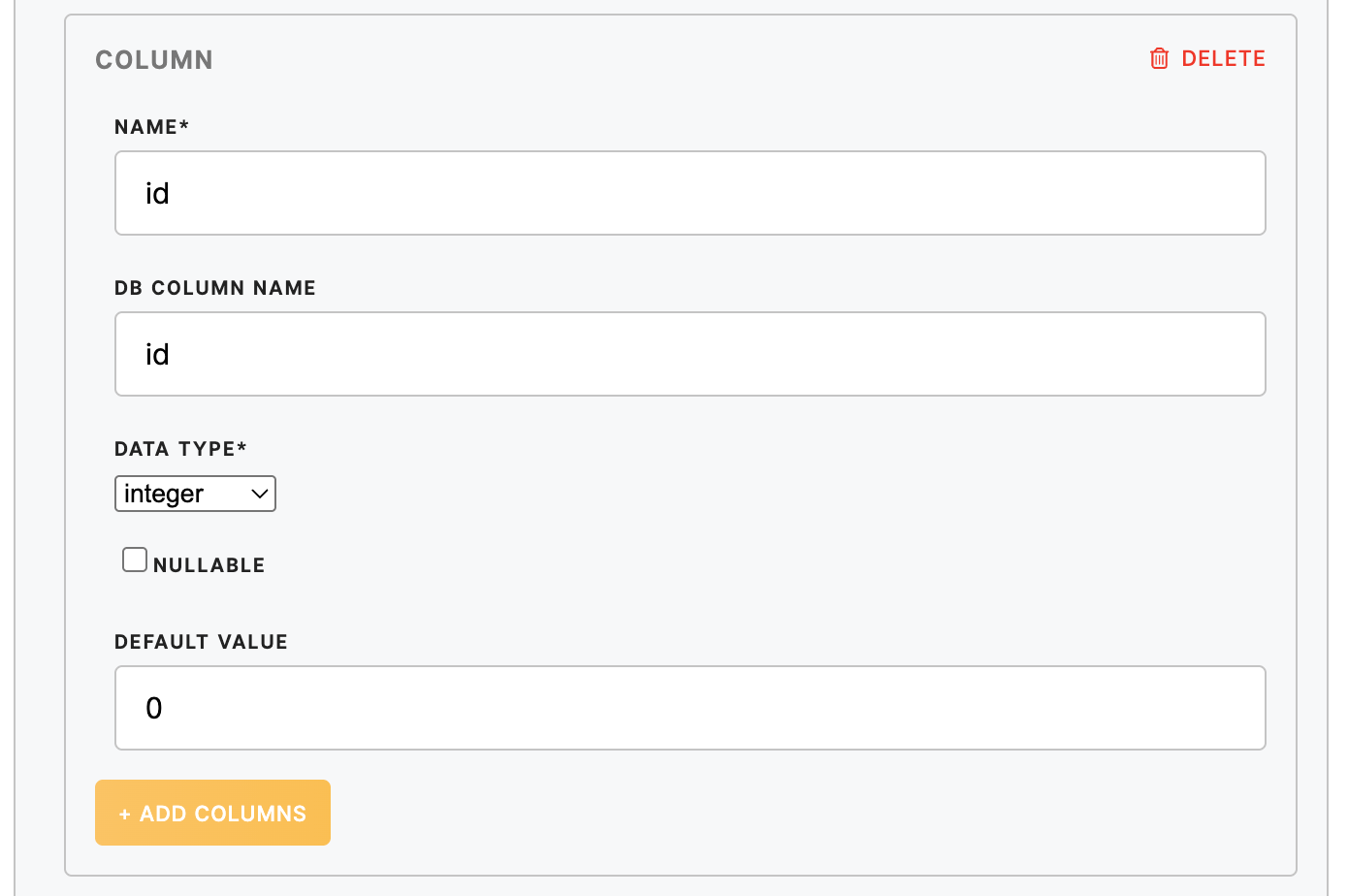
| Column Name (required) | Refers to the column in the input CSV file. |
| DB Column Name (required) | Refers to how this column will be named in the destination database. |
| Data Type (required) | The data type used in the column. Supported: integer, boolean, varchar, text, date, timestamp, biginteger, float, real, time, json |
| Nullable (optional) |
If checked, then the data with empty strings are loaded as NULL values in the destination database (in this case, is_nullable = YES). If unchecked and the data contains empty strings, then the loader returns an error message. For example: “Cannot insert the value NULL into column XY, column does not allow nulls. INSERT fails.”
Warning: All columns listed as primary keys should have unchecked Nullable (is_nullable = NO), otherwise, the loader throws an error “Cannot define PRIMARY KEY constraint on nullable column”. |
| Default Value (optional) | The default value is inserted for empty values in the column. For example, inserts NULLs in the destination columns database for empty strings in csv file. - inserts - for empty strings. |
DB
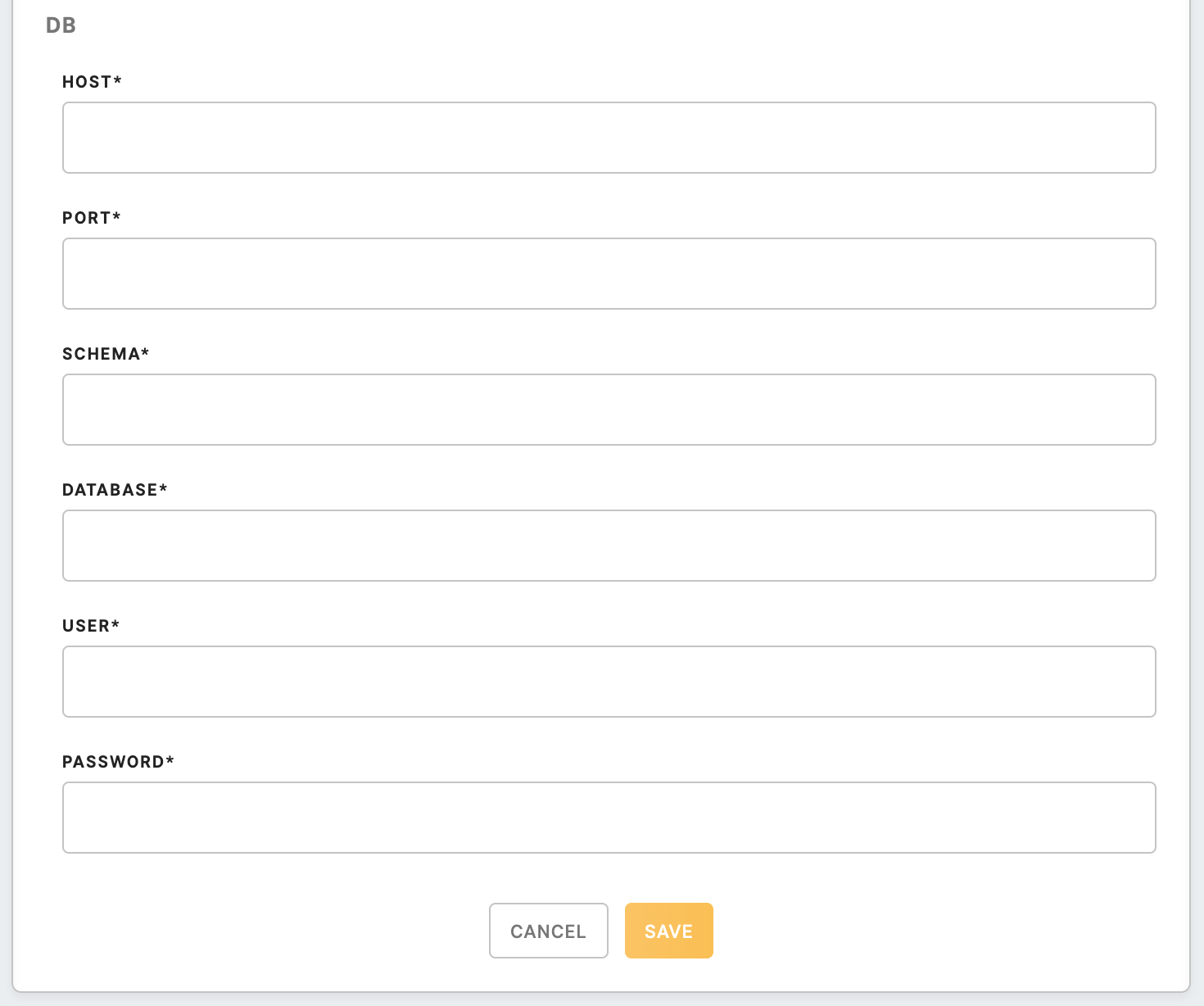
| Host (required) | Name of the server that hosts the database. |
| Port (required) | The port number you want to access. |
| Schema (required) | Organization unit in the database. |
| Database (required) | Name of the database. |
| User (required) | Account name. |
| Password (required) | Account password. |
Remember: You should be able to get all the credentials from the database administrator.
No Comments