Connector Snowflake
Snowflake is a cloud-based data warehousing platform that revolutionizes how organizations manage and analyze their data. With its unique multi-cluster, multi-cloud architecture, Snowflake enables seamless data sharing and collaboration across various platforms. When used as a connector to export data from Snowflake to a CDP, Snowflake plays a key role in facilitating the secure and efficient transfer of structured and semi-structured data. This connection enhances data-driven decision-making by ensuring that customer data is readily available and actionable within the broader context of marketing, analytics, and other customer-centric initiatives.
Learn more: about the Snowflake connector from here.
Data In/Data Out
|
Data In |
N/A |
|
Data Out |
Loaded tables will be visible in
Remember: Snowflake is able to handle very large data. Usually, when you have such large datasets, you do not store them in 1 file, Because files have a size limit and it is hard working with 1 file compared with hundreds of small files (eg. better for parallelization of calculations). Hence, each query is output into a folder as a set of
Learn more: about combining gzip files here.
Learn more: about gunzip here.
|
Learn more: You can read more about the folder structure here.
Parameters
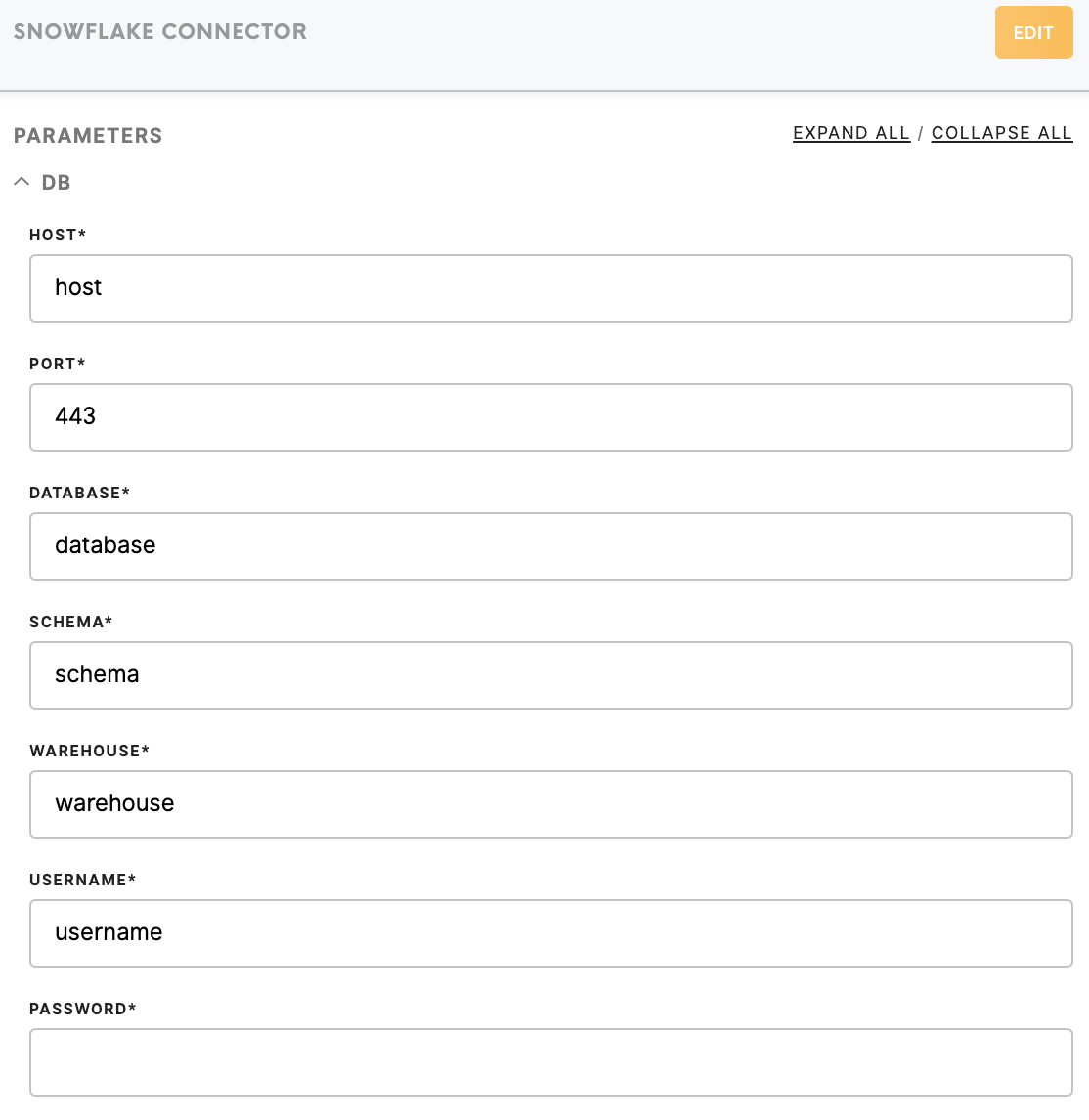
Fill credentials to connect to the Snowflake database:
- Host
- Port
- Database
- Schema
- Warehouse
- Username
- Password
Table
Define which table you wish to load, how will it be named and how the output will be.
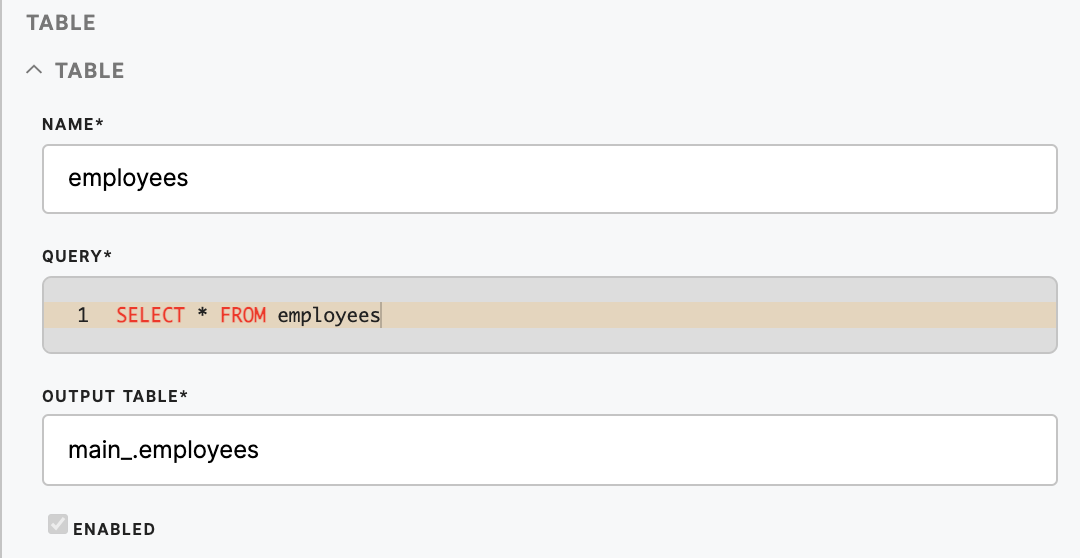
|
Name (required) |
Name of the table. |
|
Query (required) |
A query is a request to access data from a database to manipulate it or retrieve it. |
|
Output Table (required) |
The name of the folder where the data will be loaded into. E.g. If the name is “employees”, then the data can be found in |
|
Enabled (optional) |
Enabled for this table to be pulled from the database. |
No Comments