Identity Stitching Setup
Learn from this article:
| Identity stitching configuration |
| Attributes calculation configuration |
| How to run attributes from scratch |
| How to run identity stitching from scratch |
| How to force cache update |
Identity stitching configuration
Identity stitching rules can be configured in Meiro Business Explorer under the Identity Stitching setting. The prerequisties to set up identity stitching rules are:
- Sources and events need to be defined
- Stitching categories need to be created.
Refer to this documentation on Identity Stitching in Meiro Business Explorer for more details. The basic steps are:
- Go to the Identity Stitching tab
- Create new stitching categories based on the events that have been set up.
- Add rules for each category for all events that the rule applies to. (eg. the "stitching_email" category may apply to web form submissions and login events)
- Refer to this documentation for examples of stitching rules you would typically create.
Know More: For instances that have multiple domains, (eg. different web properties), it is recommended to have Cross-domain tracking to track the same web visitor across different sites. In this case, the "inbound_user_ids" field in the payload will be used for identity stitching, it is an array containing a list of meiro cookies.
Example identity stitching rule to stitch Meiro User ID across domains.
json_array_elements_text(
json_build_array(
payload->>'user_id',
payload->'inbound_user_ids'->>0
)
)Best Practice: For Meiro User ID, always name this stitching category 1PT Meiro Web ID
Attributes calculation configuration
attributes table is in public schema
Basic principle of attributes calculation is to define the attributes' definition. To help with that, we have prepared a few basic types of attributes. If pre-defined attribute types do not cover what you need, you can create custom ones.
Apart from pre-defined typed attributes, there is one more distinction. The way how attributes are calculated is that for the attribute query calculating the value only events belonging to the customer entity are available.
Create attribute definitions in Meiro Business Explorer in the Administration/Entities/Attributes tab, more details here.
You will define the attribute definition under the "definition" section in the attribute setup after clicking on "Create Attribute".
The fields in configuration stand for:
| sources, types, version | a filter for customer events. Filters only customer events you want the attribute to be calculated on. If empty, it means "all" (default empty) |
| type | type of calculation (see below, required) |
| value | value extracted from payload, usually PostgreSQL JSON value expression (required) |
| outer_value | value extracted from value (one above) - used for multi level extraction (default "value") |
| weight | weight of value, used for most_frequent, least_frequent calculation types if one customer event contains value with its weight (default 1) |
| outer_weight |
weight for the value extracted from value (default 1) |
| filter | additional filter you can apply on the customer events, any valid PostgreSQL expression (default empty) |
| outer_filter | filter applied on the value extracted from value (default empty) |
Predefined calculation types:
- avg
- first
- last
- least_frequent
- list (list of all unique values)
- max
- min
- most_frequent
- num_of_unique (number of unique values)
- sum
- value (first value we find - no ordering)
- custom
If you want to define your own custom attribute, create a custom SQL query, with "base" as the table like so (note that comments are not allowed in the definition):
SELECT count(*) AS value FROM baseWhere base is a table available in the query that holds all customer events for the customer entity that is being calculated. It has a header: id, source_id, type, version, event_time, payload
Please beware that the custom query MUST return only 1 column with a name value. Do not forget that, please.
The query must return always 1 column, can return 0 to N rows.
Context queries
However, there are attributes that do require some context about other customer entities, like engagement attributes. For this case, there is a concept of context table available to your query, which behaves like a key-value store holding results of queries ran on the whole customer base.
Imagine you need information about the 0.9 percentile of customer events count on the whole customer entities base. In contex which is defined like this:
CREATE TABLE public.context (
key text PRIMARY KEY,
value text,
query text,
modified timestamp without time zone
);
CREATE UNIQUE INDEX context_pkey ON cdp_attr.context(key text_ops);You can define a key maximum_perc_all, with query:
with tmp as (
select max(value) as value, ntile * 10 as percentile
from (select customer_events_count as value, ntile(10) over (order by customer_events_count) as ntile
from public.customer_attributes
where customer_events_count is not null) as buckets
group by 2
order by 2
)
select jsonb_object(array_agg(value)::text[], array_agg(percentile)::text[])::text as value
from tmpOnce you that, next time the component runs and it gets to the attribute calculation, before it starts with actual calculation for each customer entity, it will run the query and store the result of it in the valuecolumn. Hence, you can use these pre-calculated values in your custom queries in attributes definition, for example like this:
SELECT count(*)/(SELECT value FROM public.context WHERE key = 'maximum_perc_all') AS value FROM baseAll values for context are updated before attribute calculation runs if they are older than 24 hours or if have not been calculated yet.
Meta attributes
Have you found yourself in a situation where you have a bunch of attributes all using same or similar logic? Something like common clean up on events before extracting a value, repeating and copy pasting the logic from one attribute to five or ten more attributes? And then when you found a problem in that cleaning logic you had to change it in all ten attributes? Well, not anymore.
If you have common thing you would like to use in multiple attributes (for example calculating all bought products and their prices, then using this information to get attributes like average price per product, total quantity, total price, average number of products per transaction...), you can define it as meta attribute (CTE, or common table expression) that you can use in any other attribute calculation. Speed and convenience, yay!
Refer to the documentation here on how to set up meta attributes. Basically you can treat them as a "table" that will be usable in attribute definitions later on. Here are some examples:
-- meta attribute
-- ID: products_bought
-- definition:
select
payload::jsonb->>'product_id',
payload::jsonb->>'quantity',
payload::jsonb->>'price'
from base
where type = 'purchase' and event_time > NOW() - '30 days'::interval
-- attribute
-- ID: avg_price_per_product
-- definition (custom query):
select avg(price) from products_bought
-- attribute
-- ID: sum_price
-- definition (custom query):
select sum(price) from products_bought;
-- attribute
-- ID: sum_quantity
-- definition (custom query):
select sum(quantity) from products_bought;How to run attributes from scratch
Cockroach Implementation
If you simply want to recalculate attributes without messing with customer events, stitching, login to your CDP database and run the script below:
Warning: this will recalculate attributes for the entire customer population!
UPDATE customer_attributes
SET calculated = NULL If you wish to recalculate attributes for a specific customer, you can run the following script:
UPDATE customer_attributes
SET calculated = NULL
WHERE customer_entity_id = '0002b1f7-53e6-9d3f-705c-68320c05baa9'How to run identity stitching from scratch
Cockroach Implementation
If you want to re-stitch all customers and re-calculate all their attributes, login to your CDP database and run the script below:
Warning: this will restitch the entire customer population!
UPDATE customer_attributes SET modified = NULL;
UPDATE customer_events SET stitched = NULL, identifiers = NULL;Explanation: Setting modified timestamp to NULL is a signal for a clean up routine to delete the customer from customer attributes and sends a command to OpenSearch to delete it from there.
Setting stitched timestamp to NULL and identifiers to NULL tells identity stitching to stitch it again.
If you wish to re-stitch a particular customer, you can run this script instead:
WITH entities AS (
UPDATE customer_attributes
SET modified = NULL
WHERE customer_entity_id = '0002b1f7-53e6-9d3f-705c-68320c05baa9' RETURNING identifiers
)
UPDATE customer_events SET stitched = NULL, identifiers = NULL
FROM entities WHERE customer_events.identifiers <@ entities.identifiersIf you need to restitch 1 or more customer entities:
First export event ids to separate table in external_data schema:
DROP TABLE IF EXISTS external_data.events_abc;
CREATE TABLE external_data.events_abc (id uuid primary key);
INSERT INTO external_data.events_abc
WITH unnested AS (
SELECT unnest(identifiers) AS identifier FROM customer_attributes
WHERE customer_entity_id = 'abc')
SELECT id
FROM customer_events
INNER JOIN unnested ON customer_events.identifier = unnested.identifier*It is possible that there are too many identifiers, and the export of event ids to external data will take too long to run. In this case, you may want to create workspace in MI to extract and then load the event ids
Query example for the connector in the MI workspace:
/*aost*/
WITH unnested AS (
SELECT unnest(identifiers) AS identifier FROM customer_attributes
WHERE customer_entity_id = 'abc'
)
SELECT id
FROM customer_events
INNER JOIN unnested ON customer_events.identifier = unnested.identifierIt’s important to add the line /*aost*/ for the query to improve the query performance by decreasing transaction conflicts, you can read more about it in CockroachDB docs here
Update entity in customer_attributes. Set its modified to NULL, which means it will be deleted (both in CR and OS), set identifiers to NULL to make sure the connection between customer_events and the entity will be deleted:
UPDATE customer_attributes
SET modified = NULL,identifiers = NULL
WHERE customer_entity_id = 'abc'; After approx 1 minute check if entities have been deleted from DB:
SELECT customer_entity_id, modified, calculated
FROM customer_attributes
WHERE customer_entity_id = 'abc';Finally update customer_events. For all of customer events belonging to this customer entity the timestamp stitched is set to NULL, which tells identity stitching to stitch it again. If there is a lot of rows, it is recommended to run the query with high priority:
BEGIN;
SET TRANSACTION PRIORITY HIGH;
UPDATE customer_events
SET stitched = NULL,
identifiers = NULL
from external_data.events_abc events
where customer_events.id = events.id::UUID ;
COMMIT;*It is possible that there will be a big amount of events to update. In that case it is recommended to run the update statement in batches using Python 3 code configuration in MI.
Example here:
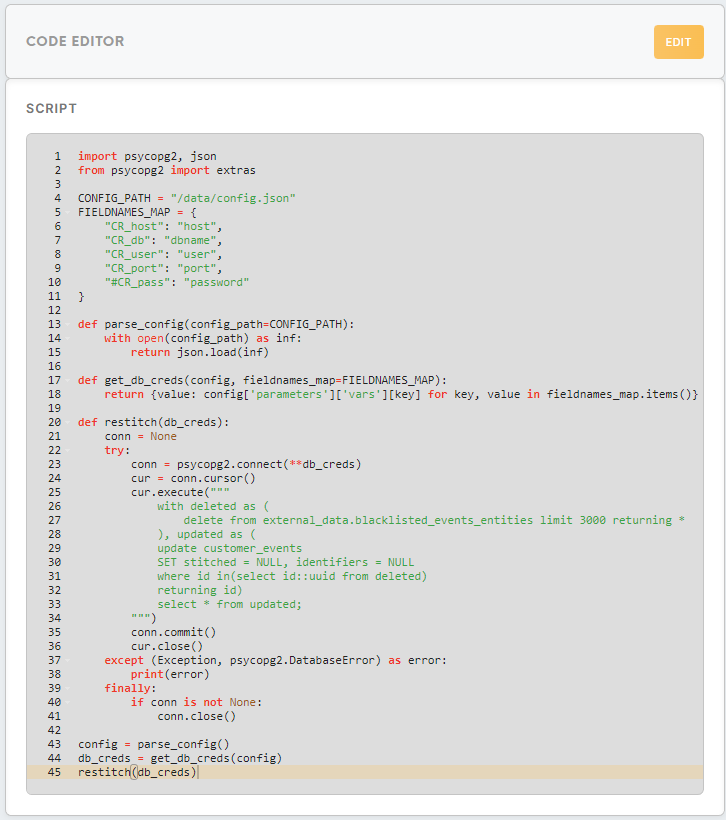
While running this code the plumbing queue needs to be monitored carefully. (Doc to monitoring on Grafana)