Tutorial: SQL on CSV processor sandbox
This article demonstrates how to create a sandbox for SQL on CSV processor in your local environment:
- When do you need it
- TextQL and how to install it
- Downloading the data
- How to write and run the query
When do you need it
When you are creating a configuration for SQL on CSV processor and writing a relatively long query can be inconvenient. This is because the query field does not show the whole code and it is needed to run configuration to test a query each time.
In this case, it is possible to recreate the SQL on CSV processor environment locally and use it as a sandbox.
This allows you to write queries locally, run and debug them without access to Meiro Integrations.
Whenever ready, you will just need to copy-paste your code into the SQL on CSV processor configuration.
TextQL and how to install it
At the backend, SQL on CSV processor uses TextQL (allows to execute SQL queries against structured text like CSV).
- macOS
Use Homebrew and run the command brew install textql in a command-line interface.
- Windows
Build it from source using Golang (you’ll need to install it first): run command go get -u github.com/dinedal/textql/….
Otherwise, use windows subsystem with ubuntu and brew your textql installation!
More details: check TextQL documentation.
Download the data
Download the data from the bucket Data Out and save to a folder on your device.
Useful commands:
cat your_file.csvto show the content of the file.
Run it either from your working directory or use the relative or absolute path to your working directory. Otherwise, first, change the folder to your working directory using the command cd which takes a directory name as an argument and switches into that directory. After that, you can run the command cat without modifications.

head your_file.csvto show the first few lines of the file.
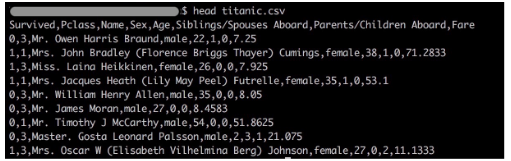
head -n 2 your_file.csvto show the first 2 lines of the file (change it to the other number of lines if needed).

Write and run the query in the command-line interface.
Using TextQL, you can write a SQL query in the command-line interface:
- Count the number of rows in the table
textql -sql "select count() from titanic" titanic.csv

-
Count the number of rows in the table considering that the table has a header
textql -header -sql "select count() from titanic" titanic.csv
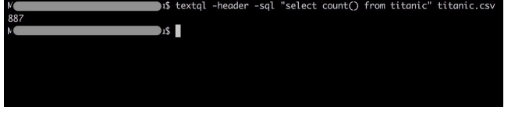
Be aware that the name of the table in the query should be written without extension: titanic (not titanic.csv).
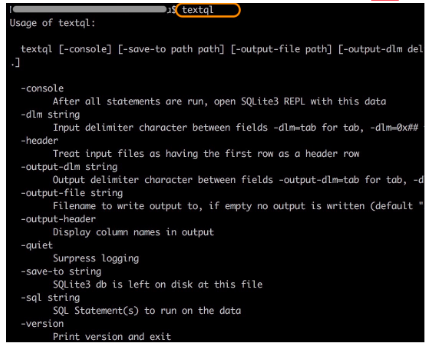
- To check all possible settings look at the documentation or simply run
textqlcommand.
Write and save the query in the file
Writing and running queries in the command-line are convenient only in the case of short and simple queries.
For more complex queries is recommended to write a query in a separate file, run it and then test it in a command-line environment.
To run the query as a bash script, the file should be with .sh extension and should start with #!/bin/sh. For writing the query you can use any code editor you like.
After saving the file in the same directory as your table (to simplify), run in the command-line interface bash scriptname.sh. The result will be shown as standard output or saved in the file depending on your script.
Examples
Below we are giving you a few examples of working with textql based on the Titanic dataset. To use them, download the dataset to your working directory.
Example 1
The simple query counts the number of rows in the table with standard output.
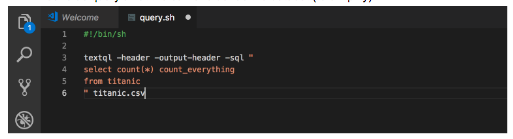
1. Paste the following code into a file in the code editor:
#!/bin/sh
textql -header -output-header -sql "
select count(*) count_everything
from titanic" titanic.csv
2. Save as query.sh at the same folder as the dataset (to simplify).
3 Run bash query.sh in the command-line.

Example 2
How to save the results of the query to the file.
1. Paste the following code into a file in the code editor:
#!/bin/sh
textql -header -output-header -output-file "output.csv" -sql "
select sex, survived, count(*) total
from titanic
group by sex, survived" titanic.csv`
The argument -output-file from the code above allows you to save the results of the query in the file.
2. Save this code in a file as query.sh at the same folder as the dataset (to simplify).
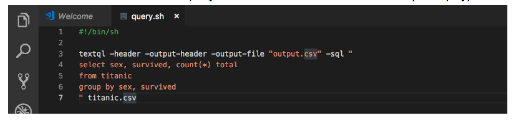
3. Run bash query.sh in command-line. There will be nothing in standard output as the results were saved in the table output.csv.

4. Check the output.csv file running the command cat output.csv.
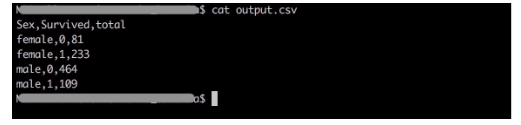
After writing and running the query, you simply need to copy-paste the SQL query to your SQL on CSV configuration and run the configuration.
Recommended articles: Processor SQL on CSV