Loader Redshift
Redshift loader enables to load of the data from Meiro Integrations to Redshift. Files from Meiro are loaded to AWS S3 bucket, from there to Redshift.
Data In/Data Out
| Data In |
In order to use a loader, files need to be stored in |
| Data Out | N/A |
Learn more: about the folder structure here.
Parameters
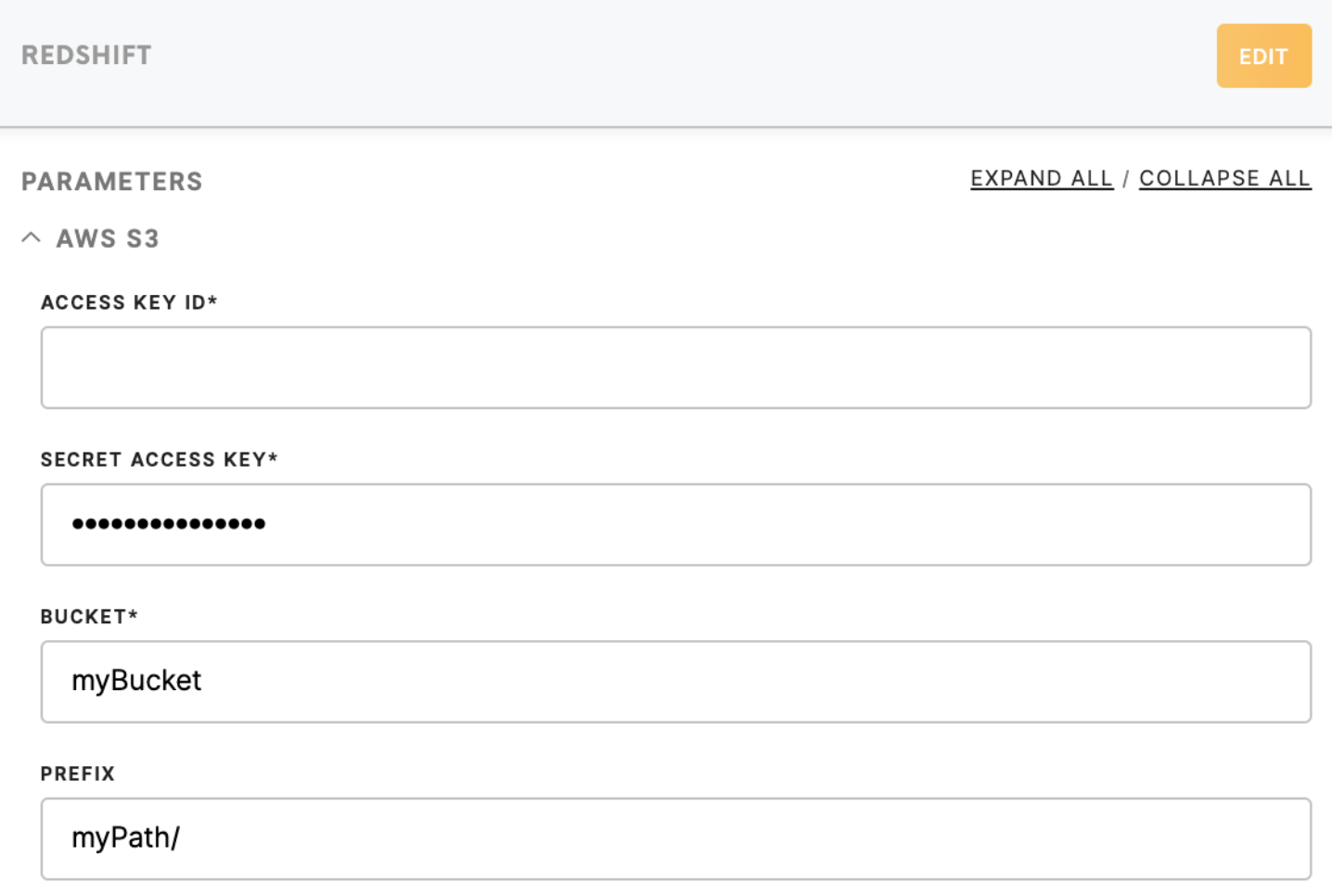
|
Access Key ID (required)
|
The AWS Access Key ID, looks like AKIA**** Create it in the Credential section of your AWS S3 account: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File
Learn more: on how to create your Redshift Access Key can be found here. |
| Secret Access Key (required) |
The AWS Secret Access Key is provided by the AWS when you create a new AWS Access Key: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File.
Learn more: on how to create your Redshift Secret Access Key can be found here. |
| Bucket (required) | Provide a Redshift bucket name which is a globally unique identifier and the region will be autodetected. |
|
Prefix (optional)
|
Provide a prefix to key names of the files
For example, if you wish to upload data in the directory |

| Host (required) | Name of the server that hosts the database. |
| Port (required) | The port number you want to access. |
| Database (required) | Name of the database. |
| Schema (required) | Name of the schema. Organization unit in the database. |
| User (required) | Account name. |
| Password (required) | Account password. |

| Enabled | Checked if SSH required to connect to database. |
| Private | Private Key. |
| Public | Public Key. |
| SSH Host | Name of SSH Host. |
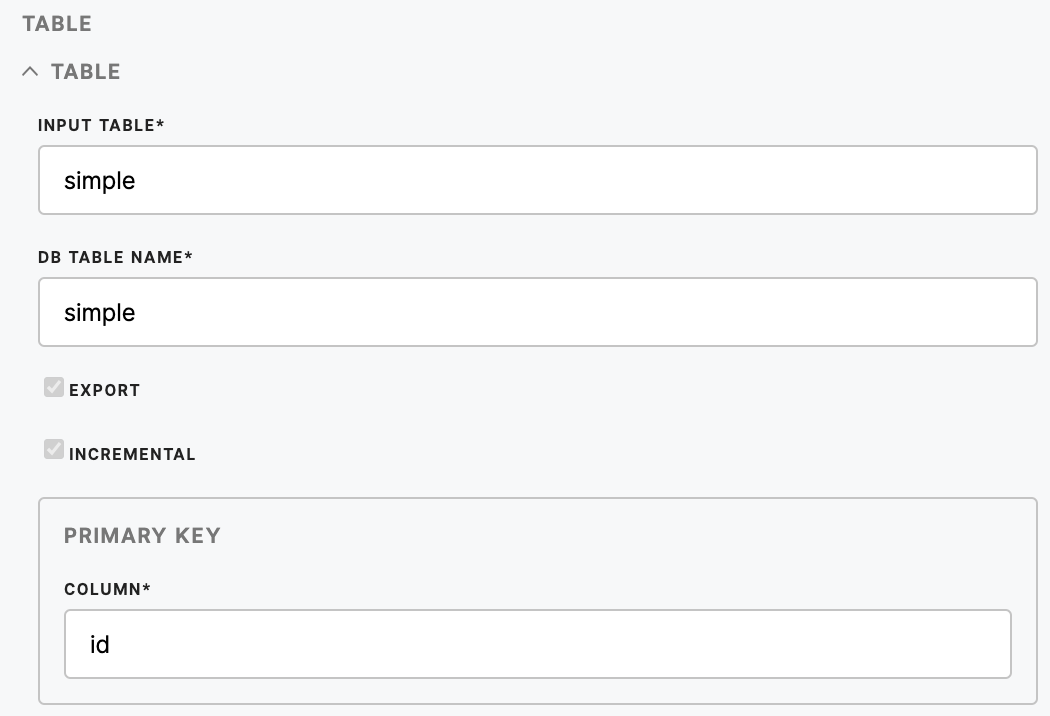
| Input Table (required) | Name of the table you want to load to the database. |
| DB Table Name (required) | Database table name. |
| Export | True if you want this table to be loaded or not. By default, it is true. |
| Incremental | Signifies if you want to load the data by overwriting whatever is in the database or incrementally. |
| Column (required) |
Can be defined for a table either when using incremental load, or not.
The primary key constraint can be defined on multiple columns or one, but cannot contain NULL values. If the incremental load is enabled, then only rows with new or updated records are inserted.
If the incremental load is disabled but the primary keys are defined: the full table is loaded (and will replace whatever is in the destination database). However, the primary key columns will show as primary keys also in the destination table structure. |

| Column Name (required) | Refers to the column in the input CSV file. |
| DB Column Name (required) | Refers to how this column will be named in the destination database. |
| Data Type (required) | The data type used in the column. |
| Size | The maximum number of digits used by the data type of the column or parameter. |
| Nullable |
If checked, then the data with empty strings are loaded as NULL values in the destination database (in this case is_nullable = YES).
If unchecked and data contains empty strings, then loader returns an error message. For example: “Cannot insert the value NULL into column XY, the column does not allow nulls. INSERT fails.”
Warning: All columns listed as primary keys should have unchecked Nullable (is_nullable = NO), otherwise loader throws an error “Cannot define PRIMARY KEY constraint on nullable column”. |
| Default Value | The default value that is inserted for empty values in the column. For example, insert NULLs in the destination columns database for empty strings in CSV file. - inserts - for empty strings. |