Loader Redshift
Redshift loader enables to load the data from Meiro Integrations to Redshift. Files from Meirot are loaded to AWS S3 bucket, from there to Redshift.
Data In/Data Out
| Data In |
In order to use loader files need to be stored in |
| Data Out | N/A |
Learn more: about the folder structure here.
Parameters
|
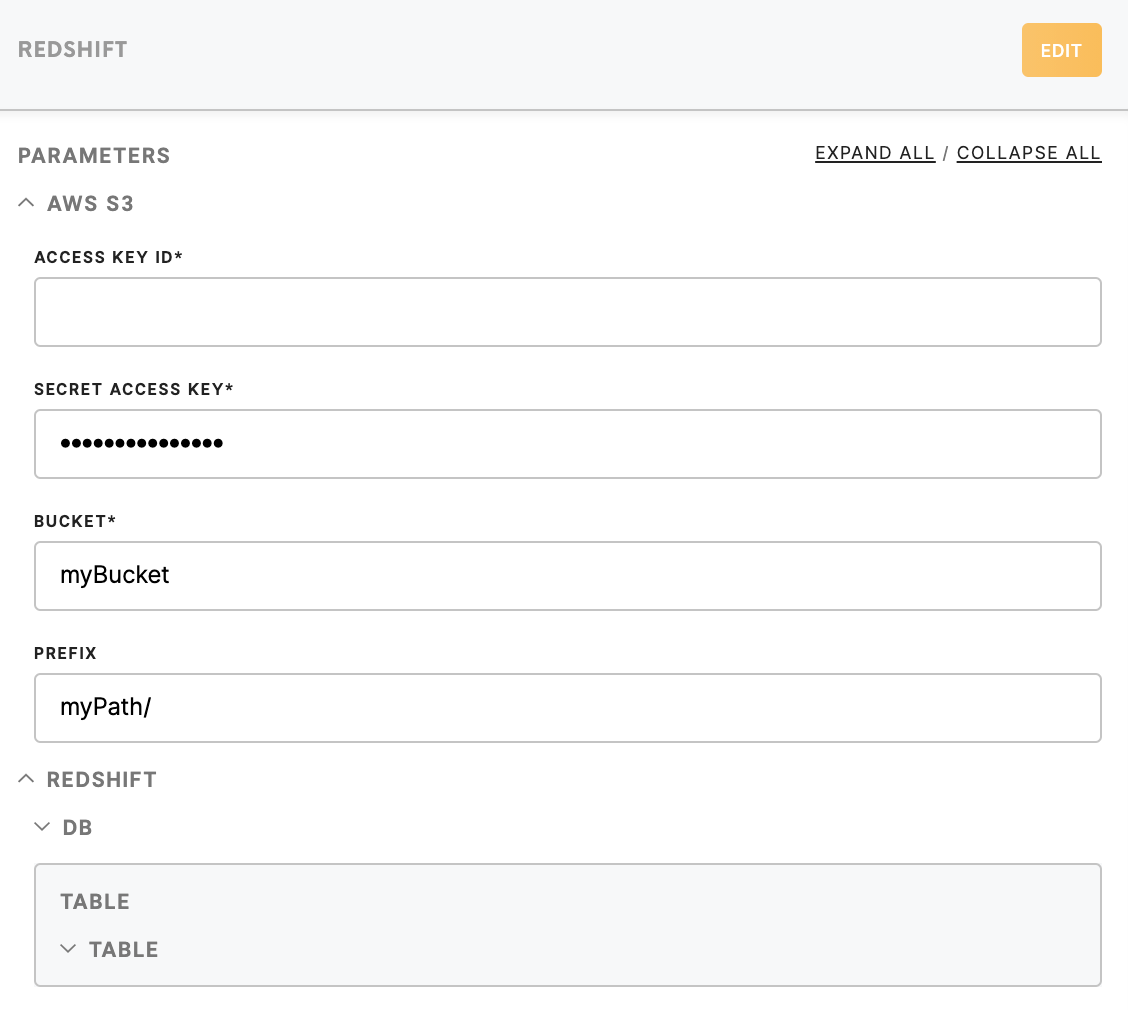
Access Key ID (required)
|
The AWS Access Key ID, looks like AKIA**** and you need to create it in the Credential section of your AWS S3 account: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File
Learn more: on how to create your Redshift Access Key can be found here. |
| Secret Access Key (required) |
The AWS Secret Access Key is provided by the AWS when you create a new AWS Access Key: My_AWS -> My Security Credentials -> Access keys (access key ID and secret access key) -> Create New Access Key -> Download Key File.
Learn more: on how to create your Redshift Secret Access Key can be found here. |
| Bucket (required) | Provide a Redshift bucket name which is a globally unique identifier and the region will be autodetected. |
|
Prefix (optional)
|
Provide a prefix to key names of the files For example, if you wish to upload data in the directory |

| Host (required) | Name of server that hosts the database. |
| Port (required) | The port number you want to access. |
| Database (required) | Name of the database. |
| Schema (required) | Name of the schema. Organization unit in the database. |
| User (required) | Account name. |
| Password (required) | Account password. |

| Enabled | If you want a certain table to be pulled from the database. |
| Private | Private Key. |
| Public | Public Key. |
| SSH Host | Name of SSH Host. |
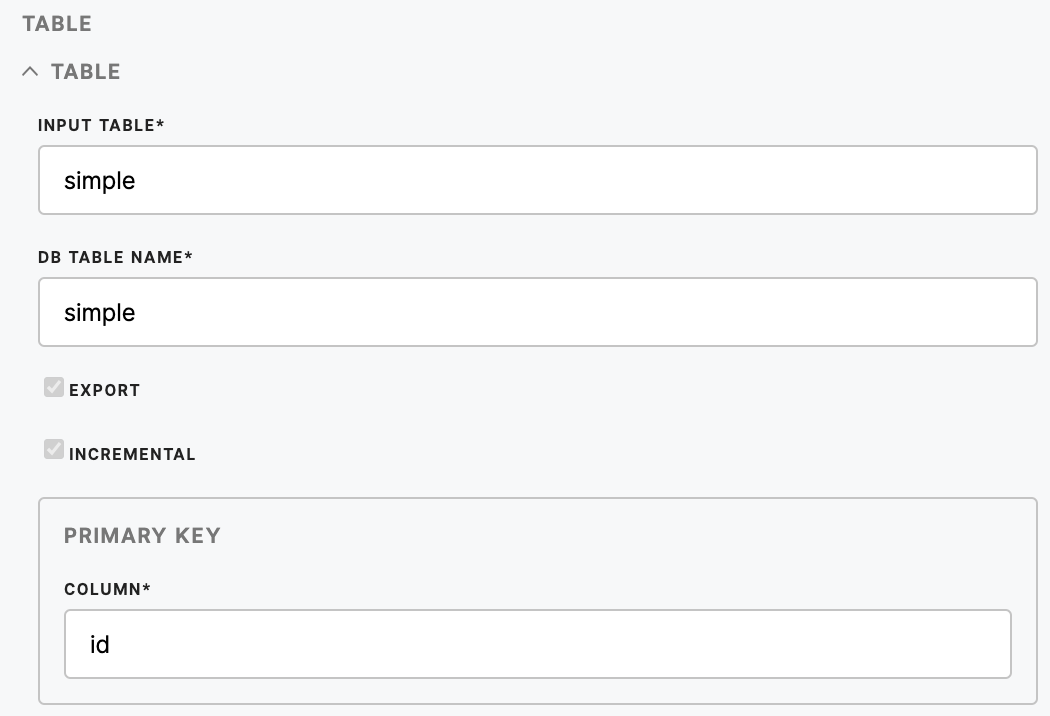
| Input Table (required) | Name of the table you want to load to the database. |
| DB Table Name (required) | Database table name. |
| Export | True if you want this table to be loaded or not. By default, it is true. |
| Incremental | Signifies if you want to load the data by overwriting whatever is in the database or incrementally. |
| Column (required) |
Defines primary key column. Can be used with incremental load. Incremental load with primary key - just rows with unique primary key will be loaded. Primary keys witnout incremental - all rows loaded, but columns set as primary key in loader will be also PKs in destination. |

| Column Name (required) | Refers to the column in the input csv file. |
| DB Column Name (required) | Refers to how this column will be named in destination database. |
| Data Type (required) | The data type used in the column. |
| Size | The maximum number of digits used by the data type of the column or parameter. |
| Nullable | If you want the value in this column to be nullable. |
| Default Value | The default value that is inserted for empty values in the column. For example, inserts NULLs in destination columns database for empty strings in csv file. - inserts - for empty strings. |