Processor Postgres
PostgreSQL, often referred to as Postgres, is an object-relational database management system.
Postgres uses and extends the SQL language combined with many other features that safely store and scales the most complicated data workloads.
The native data types that are supported include:
| Primitives | Integer, Numeric, String, Boolean |
| Structured | Date/Time, Array, Range, UUID |
| Document | JSON/JSONB, XML, Key-value (Hstore) |
| Geometry | Point, Line, Circle, Polygon |
| Customizations | Composite, Custom Types |
Learn more: about Postgres from PostgreSQL tutorials.
The Postgres processor is used to process the data by using the PostgreSQL database and SQL queries.
Requirements
Credentials of the database you would like to connect to:
- Host
- Port
- Username
- Password
If you wish to connect to a database outside of the Meiro Integrations environment, you may need a front-end tool like PgAdmin4, Postico, DBeaver, or any other front-end (GUI) tool available online. To learn more about these tools, please refer to their respective documentation online. Connecting via a GUI tool is not mandatory, but it may be useful if you want to access the database outside the Meiro Integrations environment.
The Postgres processor creates a new (“temporary”) database on the server where the input CSV files are loaded. After the input queries are evaluated, the database is deleted. This means you cannot reference or modify any tables in other databases on the server. This is a security precaution so that the user is not able to damage other databases and/or workflows.
Postgres components work only with CSV tables. Other data formats need to be converted to CSV format by processors.
Learn more: PostgreSQL documentation
Data In/ Data Out
|
Data In |
The input data should be located in the folder in/tables in CSV format. |
|
Data Out |
Output files will be written in CSV format in the folder The name of the file will correspond to what you have chosen in the Output Mapping section: |
Learn more: about the folder structure here.
Parameters

Postgres server & sandbox
|
Prepare Sandbox (optional) |
You can activate the sandbox by ticking the Prepare Sandbox checkbox. The sandbox allows you to work with SQL language on the files from the bucket Data In. You can test your query under a separate link which will be available when you have activated your sandbox. You can read more about the concept of the sandbox in the articles available online. Learn more: How to use sandbox in Postgres processor tutorial. It is possible to use the Postgres processor without the sandbox as well. In this case, you will need to fill in all the credentials described below without ticking the Prepare Sandbox checkbox. |
|
Postgres Server (required)
|
The Postgres Server section refers to the credentials of the Postgres backend server. The following credentials are mandatory and you should get them from the database administrator:
|
Input Mapping
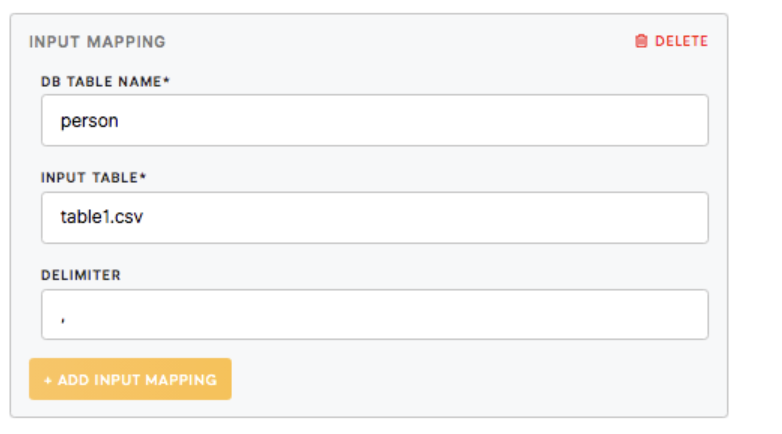
The Input mapping section relates to the table that you wish to load onto the Postgres server.
| DB Table Name (required) |
The name of the table that will be created in the Postgres database. It will be available for the sandbox and the transformation. |
| Input Table (required) | The name of the table from the bucket Data In you would like to work on. |
| Delimiter (optional) | A delimiter is a sequence of one or more characters used to specify the boundary between separate, independent regions in data streams. For CSV files, it is a comma. |
Output Mapping
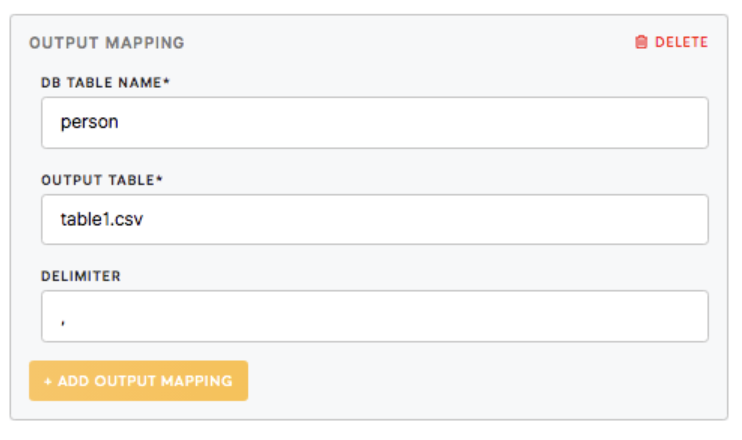
The Output mapping section relates to the table that you wish to export to the Data Out bucket.
| DB Table Name (required) | The name of the table saved on the server after processing the data with SQL query. |
| Output Table (required) | The name of the table that you would like to see in the Data Out bucket. |
| Delimiter (optional) | A delimiter is a sequence of one or more characters used to specify the boundary between separate, independent regions in data streams. For CSV files, it is a comma. |
Code Editor, SQL Script
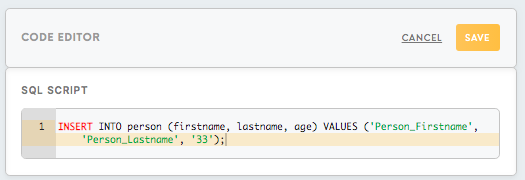
To process the tables from the Data In bucket, you will need to create an SQL script. You can copy-paste here as well script already created in the SQL sandbox.
Learn more: how to execute SQL queries in a sandbox, you can refer to this tutorial.
Learn more: Tutorial: How to use the sandbox in the Postgres processor
Learn more: How to search & replace within a code editor