Connector Google BigQuery
Google BigQuery connector is used to enable programmatic read/write access to BigQuery.
Google BigQuery provide easy solution to load data from Google BigQuery to Keboola Connection.
Main functionality
- execute query in BigQuery
- extract query result to Cloud Storage
- download extracted data from Cloud Storage
- cleanup Cloud Storage of extracted data
Data In/Data Out
Data In
N/A
Data Out
Your results will be saved in the Data Out bucket data/out/files folder.
Read more: about the folder structure here.
Learn how: to move files from one folder in configuration to another using Command Line Interface Code processor please refer to this article.
Parameters
The Google section
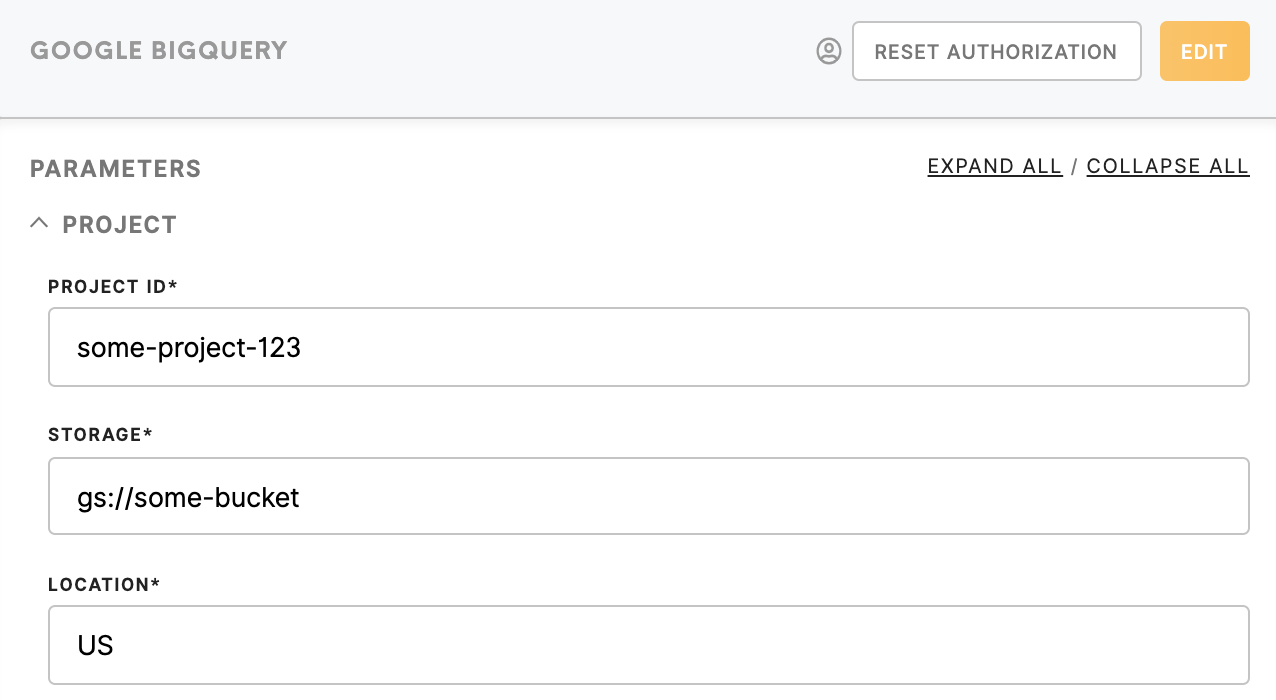
Project ID (required)
ID of the BigQuery project that will be billed for the job.
Storage (required)
URL of existing Google Cloud Storage bucket, where data will be exported.
Location(required, default US)
The geographic location where the job should run and source data exists.
The Query section
It defines queries used to fetch data.
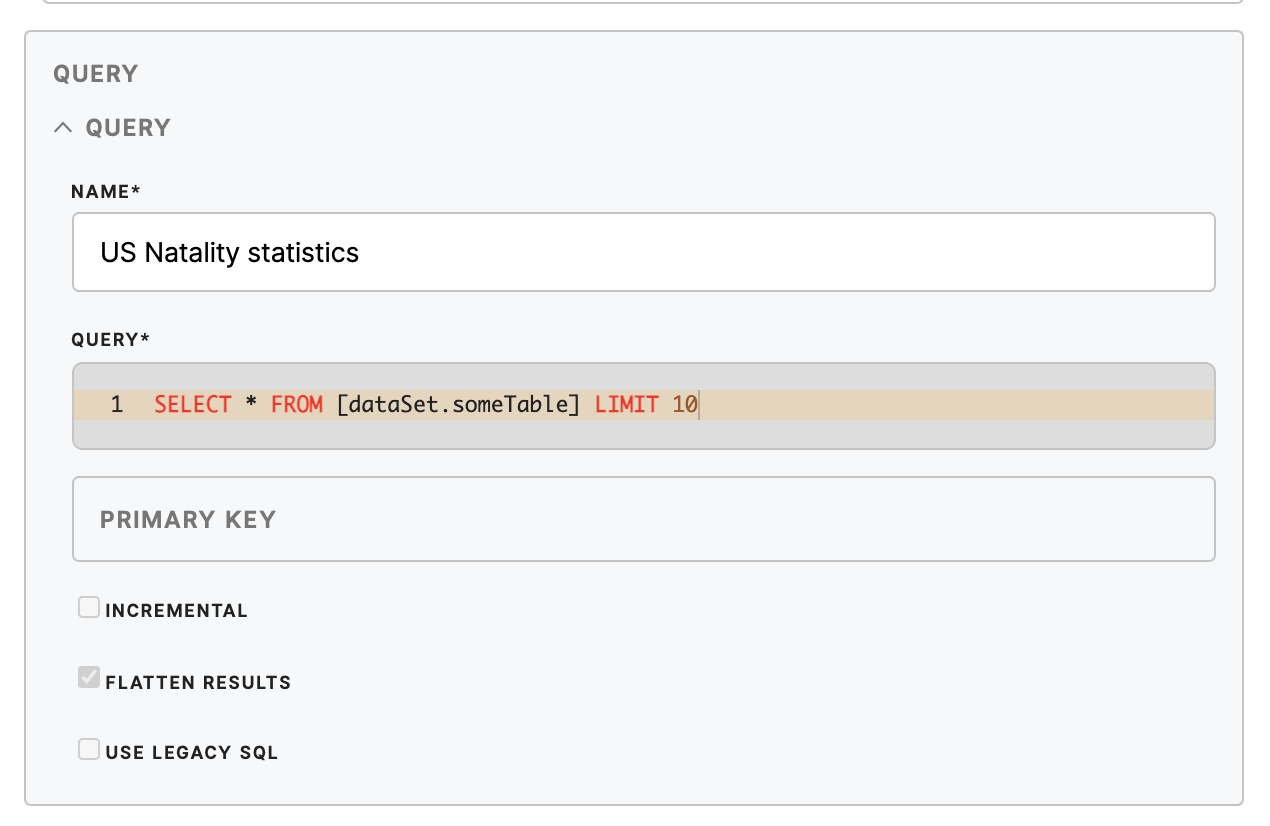
Name (required)
Query name
Query (required)
query in BigQuery Syntax (https://cloud.google.com/bigquery/query-reference)
Primary key (optional)
primary key in Keboola Connection
Incremental (optional)
Use incremental import to Keboola Connection (default is false)
FlattenResults (optional)
Flattens all nested and repeated fields in the query results. (default is true)
UseLegacySQL (optional)
Use legacy SQL to run query. Set false to use standard SQL (default is true) (https://cloud.google.com/bigquery/docs/reference/standard-sql/)
outputTable(optional)
destination table ID in Keboola Connection (if empty, will be generated automatically from query name)
enabled (optional)
process extraction of this query (default is true)
Google is slicing large results to multiple files. Primary key should be defined.