Connector Google BigQuery
Google BigQuery connector is used to enable programmatic read/write access to BigQuery.
Google BigQuery provide easy solution to load data from Google BigQuery to Keboola Connection.
Main functionality
- execute query in BigQuery
- extract query result to Cloud Storage
- download extracted data from Cloud Storage
- cleanup Cloud Storage of extracted data
Data In
In/Data Out
Data In
N/A
Data Out
Your results will be saved in the Data Out bucket data/out/files folder.
Read more: about the folder structure here.
Learn how: to move files from one folder in configuration to another using Command Line Interface Code processor please refer to this article.
Parameters
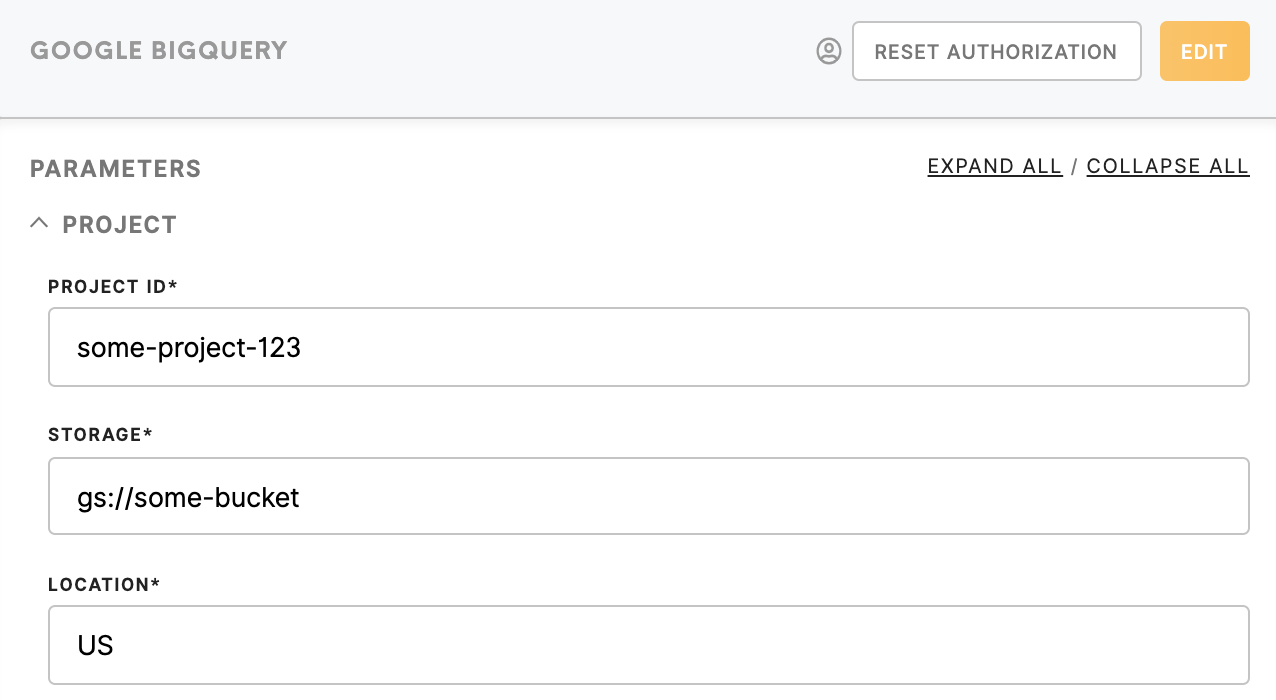
The Google section
Project ID (required)- ID of the BigQuery project that will be billed for the job.
Storage (required)- URI URL of existing Google Cloud Storage bucket, where data will be exported.
location (Location(optional, default US) - The geographic location where the job should run and source data exists.
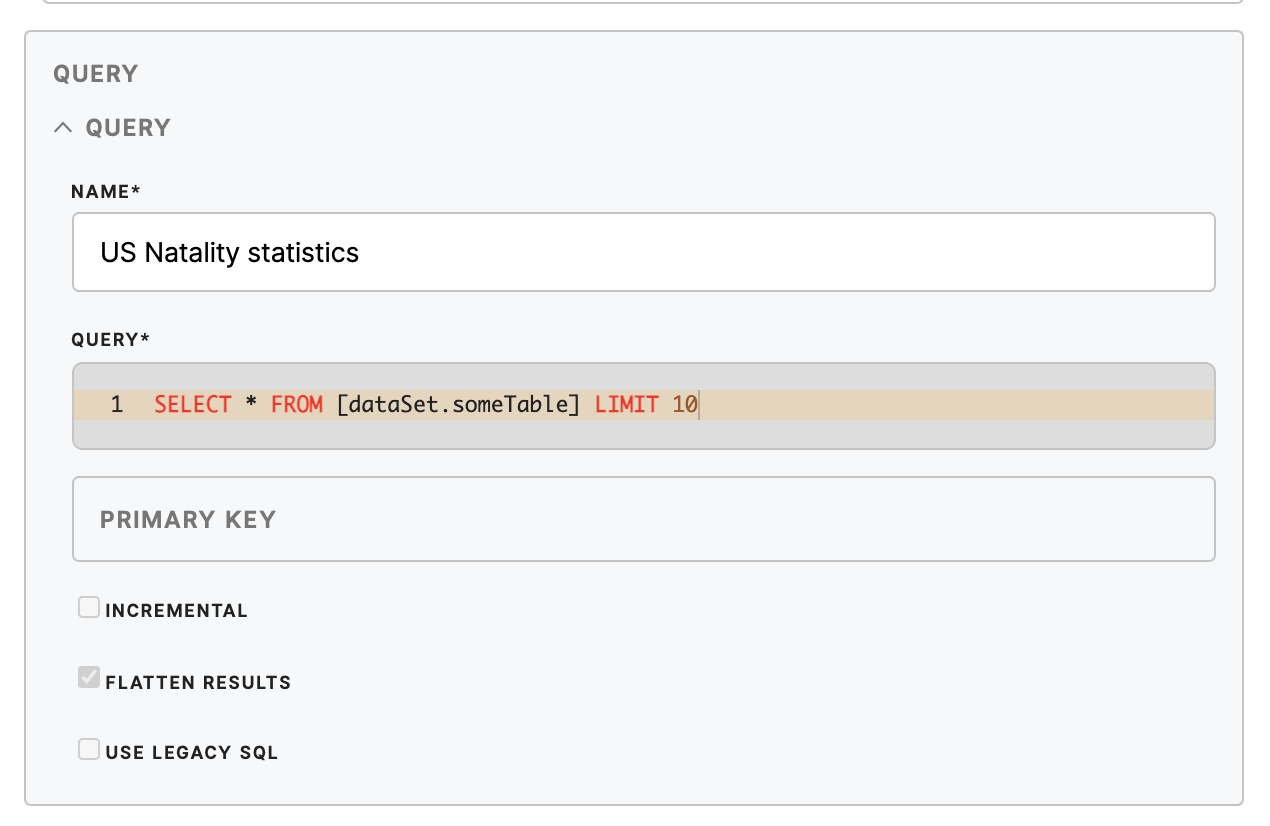
The Query section defines queries used to fetch data
- (required)
name- query
Query namequeryQuery (required)
-
query in BigQuery Syntax (https://cloud.google.com/bigquery/query-reference)useLegacySqlUseLegacySQL (optional)
-
Use legacy SQL to run query. Setfalseto use standard SQL (default is true) (https://cloud.google.com/bigquery/docs/reference/standard-sql/)flattenResults- (optional) Flattens all nested and repeated fields in the query results. (default is true)-
outputTable(optional) - destination table ID in Keboola Connection (if empty, will be generated automatically from query name)primaryKey(optional) - primary key in Keboola Connectionincremental(optional) - use incremental import to Keboola Connection (default is false)enabled(optional) - process extraction of this query (default is true)
Google is slicing large results to multiple files. Primary key should be defined.
Name