Processor Python
The Python processor allows you to transform the data using Python scripts. Python is an interpreted high-level programming language for general-purpose programming. Because of its convenience, it is becoming very common for solving data analytics problems such as data cleaning and analysis.
Requirements
You need to have basic experience in programming and be comfortable with Python syntax to work with the Python processor component. Topics you need to be familiar with include (but are not limited to):
- Data structures
- Control flow tools
- Working with files (opening, reading, writing, unpacking, etc.)
- Modules and packages
We recommend you to begin with the official Python tutorial if you are not familiar with Python syntax but have experience in programming in other languages. If you are a complete novice in programming, we suggest reading tutorials for beginners.
Links
Features
OS Debian Jessie
Version Python 3.6
Packages pre-installed
apache-libcloud, awscli
beautifulsoup4, boto
cx_Oracle
flake8
GitPython, google-api-python-client, google-auth-httplib2, google-cloud-bigquery, google-cloud-storage
html5lib, httplib2
ijson
ipython
Jinja2, jsonschema
lxml
matplotlib, maya
numpy
oauthlib
pandas, pandas2, pymongo, pytest, python-dateutil, PyYAML
requests, requests-oauthlib
scikit-learn, scikits.statsmodels, scipy, seaborn, simplejson, SQLAlchemy, statsmodels
tqdm
urllib3
Data In/Data Out
Data In
Files for processing and transformation can be located in in/tables/ (CSV files) or in/files/ (all other types of files) folder. The location depends on the previous component in the dataflow and the type of the file.
Data Out
Output files should be written in out/tables (CSV files) or out/files (all other types of files) folder. The location depends on the need for the next component and the type of the file.
To learn more about folder structure in configuration please refer to this article.
Parameters
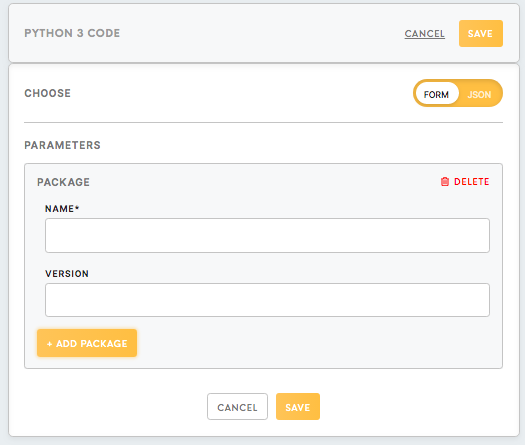
Package
The Python processor component comes pre-installed with the most common packages, but it is possible to install additional packages if needed. Packages are installed using pip utility and generally, all the packages available on pypi.org can be installed. However, if you get stuck with external dependencies, you can contact our developer team.
For installing a package, provide:
- The name of the package (required).
- The version of the package (optional). If not provided, the latest version of the package will be installed.
Code Editor
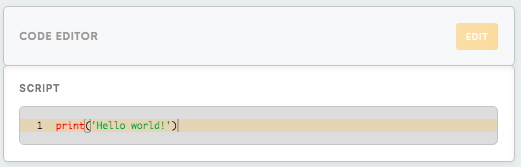
Script
This field is intended for the Python script that you write to process the data.
Script location and paths
A script file is located in the /data folder. For accessing the data files, you can use an absolute or relative path.
Input files
- an absolute path
/data/in/tables/..and/data/in/files/.. - a relative path
in/tables/..andin/files/..
Output files
- an absolute path
/data/out/tables/..and/data/out/files/.. - a relative path
out/tables/..andout/files/..
Standard output
The analogue of console log in Meiro Integrations is the activity log. If you run `print(“Hello world!”)` script in the configuration, the system will write the result in the activity log.
Indentation
The script field supports indentation, which is the important feature of Python syntax, and creates indent automatically when changing to a new line if needed. Be sure not to mix tabs and spaces when you copy and paste scripts written in your local IDE.
Script requirements
While working with dataflow, you will need to work with files and tables a lot. Generally, you will need to open the input file, transform the data and write it in the output file. There are no special requirements to the script except the Python syntax itself. You can check a few examples of scripts that help solve common tasks in the section below.
Examples
Example 1
This example illustrates a simple code that imports an open dataset from an external source, writes it to an output file in a new folder and prints a standard output to the console log. Usually, you will need to open the file from the input bucket, which was downloaded using a connector, but in some cases requesting the data from external resources can be necessary.
#import necessary libraries
import requests
import pandas as pd
import os
#request url and save response to variable
url = 'http://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
r = requests.get(url)
#create new folder for output
if not os.path.exists('/data/out/newfolder/tables/newfolder'):
os.makedirs('/data/out/tables/newfolder')
#create or open (if exist) output file for writing and write the content of the response
with open('out/tables/newfolder/titanic.csv', 'wb') as f:
f.write(r.content)
#read output file and print to console log first 10 rows
data = pd.read_csv('out/tables/newfolder/titanic.csv', header=0)
print(data.loc[0:10,["Name", "Survived"]])Example 2
This example illustrates opening, filtering and writing CSV file using pandas, which is one of the most common Python libraries for data analytics. In this script, we will use Titanic dataset which contains data of about 887 of the real Titanic passengers. This dataset is open and very common in data analytics and data science courses.
Let’s imagine we need to analyze the data of male and female passengers separately and want to write the data in 2 separate files. Data in this example was previously downloaded using the connector component, we’ll show below how you can reproduce the code on your computer.
#import pandas library
import pandas as pd
#read data from file and keep it in data variable
data = pd.read_csv('in/tables/titanic.csv')
#filter rows with male and female passengers, keep data in variables
data_male = data[data['Sex']=='male']
data_female = data[data['Sex']!='male']
#reset indexes to each dataset so it starts from 0 and grows incrementally
data_male.reset_index(drop=True, inplace=True)
data_female.reset_index(drop=True, inplace=True)
#write data to output files
data_female.to_csv('out/tables/titanic_filter_female.csv')
data_male.to_csv('out/tables/titanic_filter_male.csv')Reproducing and debugging
If you want to reproduce running the code on your computer for testing and debugging, or you want to write the script in a local IDE and copy-paste it in Meiro Integrations configuration, the easiest way will be to reproduce the structure of folders as below:
/data
script.py
/in
/tables
/files
/out
/tables
/filesThe script file should be located in the /data folder, input files and tables in the folder in/ in the corresponding subfolders, output files, and tables in output/files and output/tables respectively.
For reproducing the example 2, you will need to download the dataset and save it to the folder /data/in/tables as titanic.csv, paste code from the example to the script file and run it. New files will be written to the folder /data/out/tables/.