Tutorial: How to implement product feed (WIP)
Here, we will provide some general guidelines on product feeds and how it can be implemented as part of the data model in CDP
Pre-requisites
The client should provide a link to their product feed. It is usually a xml, html, or csv file with important information about their products. Here are the important fields that a product feed must have to fulfill a majority of our use cases.
| Field | Description |
| Product ID |
The ID of the product, also referred to the SKU sometimes. Ensure that the Product ID matches with the product IDs from other sources of data (Purchase, cart events from Meiro Events, transactions from their POS database etc) |
| Product Name | Name of the product |
| URL | The link to the product's page of the website |
| Image URL |
A publicly accessable link to the image of the product. The link usually ends with .jpg .jpeg or .png The product image is often attached to emails or other activation mediums. |
Here are some useful but not necessary fields in a product feed. They are useful for specific use cases.
| Field | Description |
| Price, Currency |
Monetary values of the product Useful in cases where you want to notify customers of a price drop |
| Brand, Category |
Fields that categorize the product |
| In Stock |
Flag that says if the product is in stock Useful in cases where you want to notify a customer that a product is back in stock |
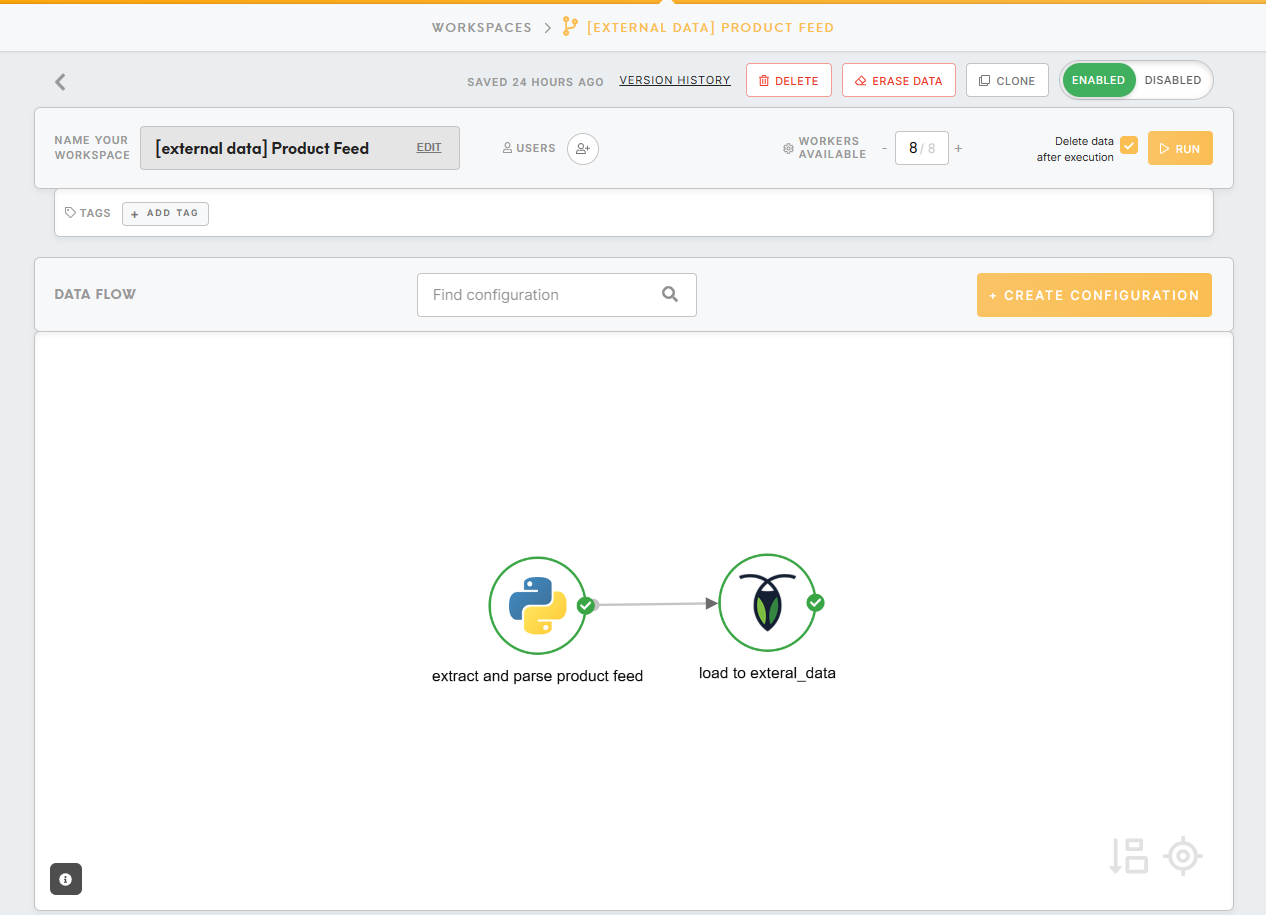
The product feed workspace
The product feed workspace can be as simple as just 2 components.
The first component is a Python processor which extracts the product feed from the link and parses the data into a csv.
The second component loads the product feed into the CDP
How to parse your product feed
If your product feed is in csv, you can use Pandas package with our Python processor to format the product feed. Here is an example script you can use to extract and parse a .csv feed. Remember that the product feed source can vary from client to client and you will have to change the script accordingly to parse the feed.
import csv
import requests
import pandas as pd
product_feed_url = 'https://feed.<redacted>.csv'
download = requests.get(product_feed_url)
decoded_content = download.content.decode('utf-8')
cr = csv.reader(decoded_content.splitlines(), delimiter=',')
list_pdts = list(cr)
# remove header row
list_pdts.pop(0)
# format feed as a dataframe with our own column names
df = pd.DataFrame(list_pdts, columns = ['product_id', 'product_name', 'url', 'img_url', 'brand', 'category', 'price', 'currency'])
df.to_csv('out/tables/product_feed.csv', index=False)if your product feed is in xml/html, you can use BeautifulSoup package with our Python processor to parse and format the product feed. Here is an example script.
import requests
from bs4 import BeautifulSoup
import pandas as pd
response = requests.get('https://feed.<redacted>.xml')
products = BeautifulSoup(response.content, "html.parser")
# in this product feed, the products are called 'entry'
# this will vary with client, so please check and change the word accordingly
list_pdts = products.findAll('entry')
# here we parse the product feed by extracting the neccesary fields
# please explore the feed and use cases to get all required fields
data = []
for pdt in list_pdts:
product_name = pdt.product_name.get_text() if pdt.product_name is not None else None
image_link = pdt.image_link.get_text() if pdt.image_link is not None else None
price = pdt.price.get_text() if pdt.price is not None else None
currency = pdt.currency.get_text() if pdt.currency is not None else None
row = [pdt.id.get_text(), product_name,
pdt.link.next_sibling, image_link,
price, currency]
data.append(row)
df = pd.DataFrame(data, columns=['product_id', 'product_name', 'url', 'img_url', 'price', 'currency'])
df.to_csv('out/tables/product_feed.csv', index=False)Where to store your product feed
Your product feed should live in the external_data schema of the CDP