Problems with large customer entities and how to investigate and solve them
Problems with large customer entities
When a customer entities grows too large, this is the following impact:
- Some attributes will be missing values.
- Some customers will be unsearchable based on attributes such as e-mail due to 1.
- Some customers will not be able to be segmented due to 1.
- Some customers will not be able to be sent to exports due to 1.
The exact reason is as follows:
While processing attributes, the algorithm only considers the latest 10,000 customer events. This is to prevent the process to be stuck on the recalculation of 1 entity, not allowing time for other entities to be processed, as you might be aware, the attribute calculations of each attribute is done on all events that belong to an entity, so you can imagine how long it would take to recalculate the attributes if the entity is too large (> 10,000 events).
Not only that, there is a limit for 250 values per attribute per entity. The reason for this is to improve search results during segmentation, which uses OpenSearch. It's usually very unlikely for attributes to have more than 250 values unless this scenario with large customer entities happen, which is why it is set to 250.
Investigating large customer entities
Other than the QA checks that you can do here, you can follow these steps as a guide in investigating a customer entity that has grown too large:
- Referring to QA checks, first you need to obtain a list of the largest customer entities.
- After which, it will be helpful to check which identifiers are contributing to the most number of events, i.e. query for stitching identifiers in the largest customer entities, and count them per entity. ( Note that this is different from the method used in QA checks "Number of unique identifiers per entity", as we are trying to get how many events a single identifier is present in, rather than the number of identifier values themselves. )
- You can also try to plot the stitching graph of the entity to narrow down the problematic identifiers, rules, or events that caused the large customer entity
Example query for 2:
Cockroach CDP version:
/*aost*/
select ca.customer_entity_id,
case when event_id in (
-- list of event ids that apply the stitching rule
) then
-- example stitching rule(s):
coalesce(payload->>'stitching_identifier', payload->'payload'->>'identifier') as
-- example stitching identifier id:
stitching_identifier_id
from public.customer_attributes ca
left inverted join customer_events as ce
on ca.identifiers @> ce.identifiers
where ce.identifiers != '{}'
where ca.customer_entity_id in
(
-- list of the largest entities
)
PostgreSQL CDP version (to be deprecated):
select
m.customer_entity_id,
case when event_id in (
-- list of event ids that apply the stitching rule
) then
-- example stitching rule(s):
coalesce(payload->>'stitching_identifier', payload->'payload'->>'identifier') as
-- example stitching identifier id:
stitching_identifier_id
from cdp_ce.customer_events ce
left join cdp_ps.matching m on ce.id::uuid = m.customer_event_id
where m.customer_entity_id in
(
-- list of the largest entities
)Example query for 3:
In your database, run the following code for your customer entity. Here we are getting the groups of identifiers from events table for a particular customer entity. Save the output as a csv with file name <client>_<customer_entity_id>.csv
select distinct ce.identifiers
from customer_attributes ca
inner join customer_events ce on ca.identifiers @> ce.identifiers
where customer_entity_id = '0000746f-7277-22ce-dc29-ba821d66cdb2'
and array_length(ce.identifiers, 1)>1Next run this python script
import csv
import ast
from pyvis.network import Network
# function to parse the parse each group of identifiers into a list
def adjacency_set_to_list(adjacency_set):
if len(adjacency_set)<2:
return []
adjacency_edge_list = []
for i in range(len(adjacency_set)):
for j in adjacency_set[i+1:]:
adjacency_edge_list.append((adjacency_set[i], j))
return adjacency_edge_list
client = '<client>'
cei = '0000746f-7277-22ce-dc29-ba821d66cdb2'
# read the csv file of identifiers and convert them into a list of pairs of identifiers
edge_list = []
with open(f'./{client}_{cei}.csv', newline='') as csvfile:
csv_reader = csv.reader(csvfile)
next(csv_reader, None)
for set_string in csv_reader:
# print(set_string)
adjacency_set = ast.literal_eval(set_string[0].replace('"{','["').replace('}"','"]').replace(',','","'))
adjacency_set.sort()
adjacency_edge_list = adjacency_set_to_list(adjacency_set)
edge_list += adjacency_edge_list
# preparing data to plot the identity graph
edge_list = list(set(edge_list))
edges_to_map = edge_list
nodes_to_map = []
for edge in edges_to_map:
nodes_to_map.append(edge[0])
nodes_to_map.append(edge[1])
nodes_to_map = list(set(nodes_to_map))
nodes_num = [*range(len(nodes_to_map))]
nodes_num_string = [str(x) for x in nodes_num]
# here, nodes_to_map are the identifiers and nodes_num are numbers corresponding to the identifiers
# this is to keep the identity graph clean with short identifier names
# you may dict_nodes_r[node_num] to get the actual identifier
# eg. if the node number displayed in the graph is 123, then dict_nodes_r[123] will print the identifier for node 123 in the graph
dict_nodes = res = {nodes_to_map[i]: nodes_num[i] for i in range(len(nodes_to_map))}
dict_nodes_r = res = {nodes_num[i]: nodes_to_map[i] for i in range(len(nodes_to_map))}
# plotting the identity graph
net = Network()
net.add_nodes(nodes_num,
label=nodes_num_string)
for edge in edges_to_map:
net.add_edge(dict_nodes[edge[0]], dict_nodes[edge[1]])
net.show(f'{client}_{cei}.html', notebook=False)The output html is named <client>_<customer_entity_id>.html and it will look something like this, please use it to identify the issue with the large entity.
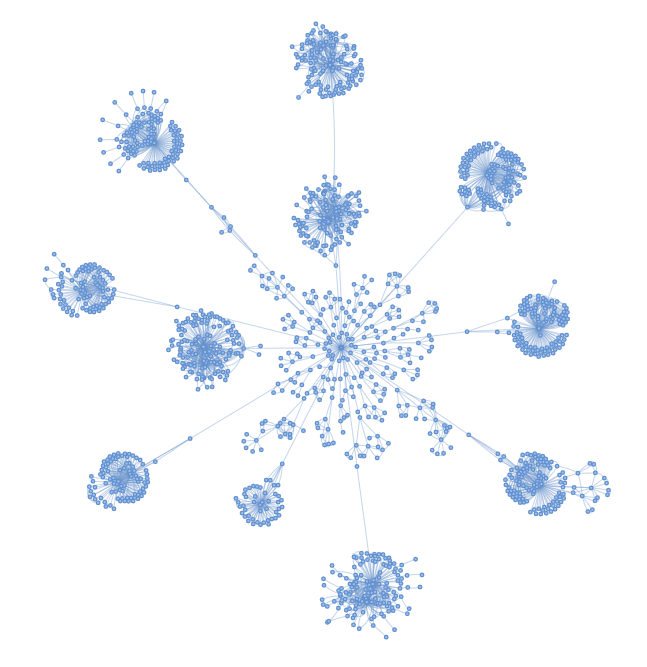
Example problems and causes
Remember that profile stitching is as good as the most unique identifier in all of the stitching rules, so most of the time problems arise due to the identifier not being as unique as it is assumed to be. It can be helpful for finding out the root cause of large entities if we draw from previous real-world examples, so here is a list of some reasons based on our experience as to why an entity can grow so large:
1. Some device identifier is being used as a stitching rule (refer to issue 3 in this doc), and many users or even test/bot users were using the same device to perform actions on website/app, which caused the profile stitching process to assume they are all coming form the same customer entity.
Solution to 1. :
There are multiple ways to solve this depending on the data available or can be made available to you. You can refer back to this doc to see if any of the solutions listed works for the root cause you're seeing.